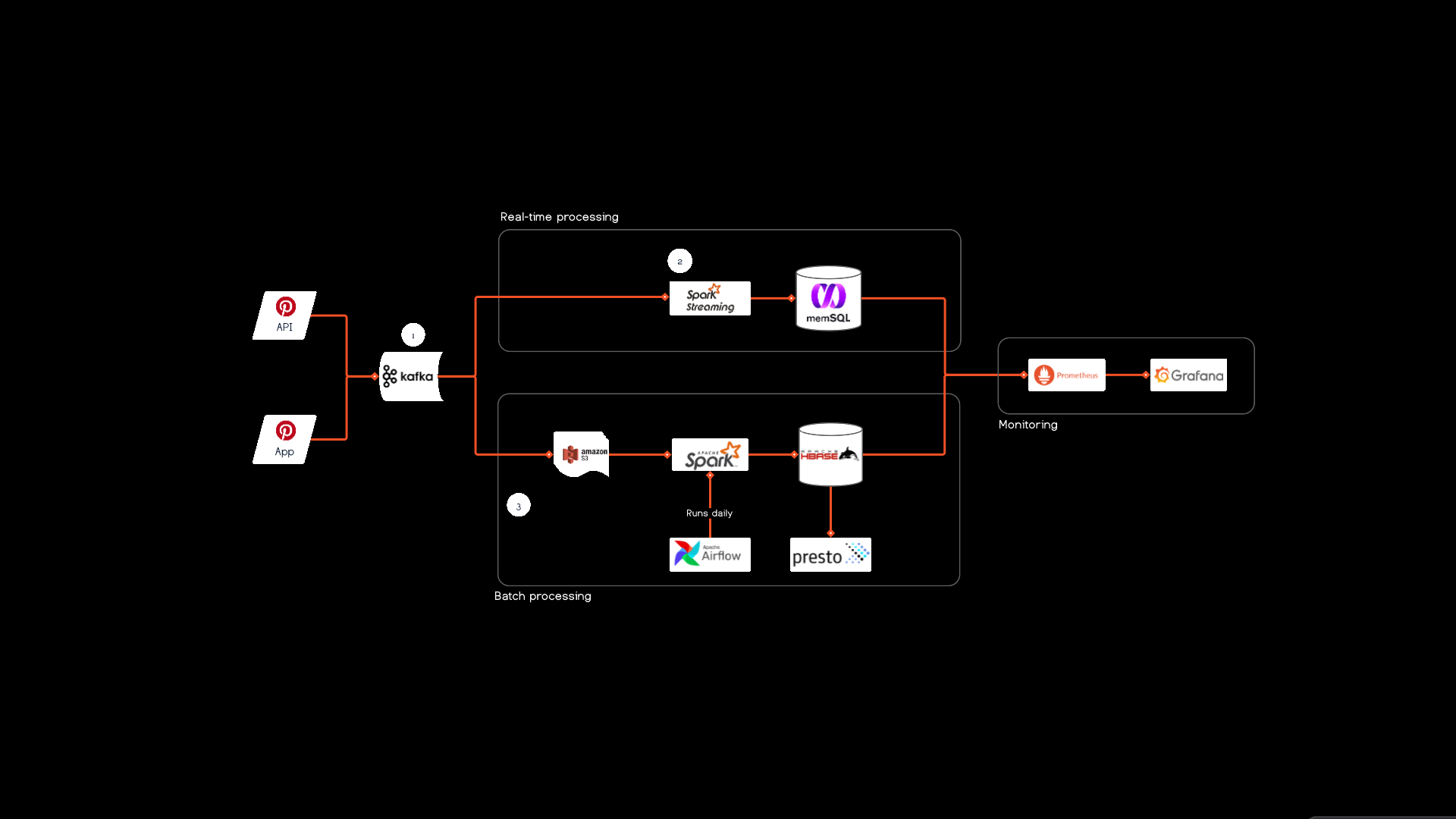
- Project aims to simulate the user-post pipeline used by Pinterest. User post JSONs are received, and processed using Lambda architecture, in batch and also real-time. Batch data is initially stored in the cloud, cleaned and stored locally, accessed with Presto and Cassandra.
- Real-time data is cleaned and monitored using Pyspark in micro-batches, and then sent to postgres.
- UML diagram of project: https://user-images.githubusercontent.com/94751059/177628201-85cafdf7-4fc1-4273-922f-a1c1ec0253b5.png
{kind=link}
- Data source: user_posting_emulation.py -an infinite posting loop, which simulates a users activity on-site and posts the JSONs to a localhost port.
- project_pin_API.py contains an API to receive the user posts, it also sets up the kafka producer to add the posts to the topic
- consumer_to_s3.py creates the Kafka consumer, and passes all messages it finds in the topic to an s3 bucket.
- s3_to_spark_connector.py then retrieves the data from the s3 bucket and passes to spark, with some initial batch data cleaning:
- Convert the follower_count into a real number. (ie 5k -> 5000)
- Change the file path into usable path. "File path is /data/post" -> "/data/post"
- Convert the list stored as a string, into an actual list. "one, two, three" -> [one, two, three]
- The cleaned userpost is then stored in Cassandra using the datastax connector, and the final line of the s3_to_spark_connector.py.
- Presto is installed, connected and used to query the cassandra database.
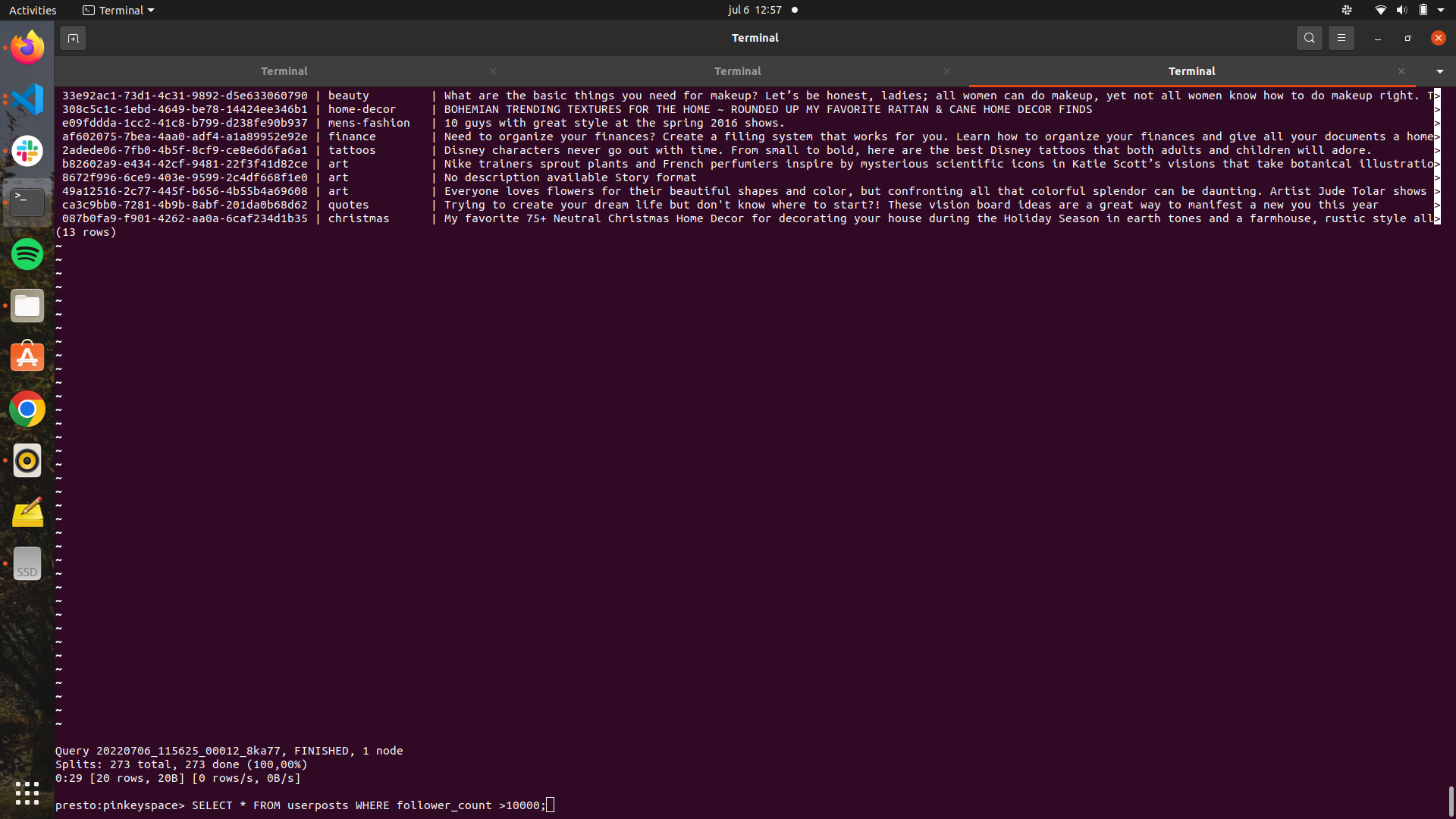{kind=link}
- Airflow is used to run s3-clean-to-cassandra job on a timer. The airflow file "pin-dag" is included.
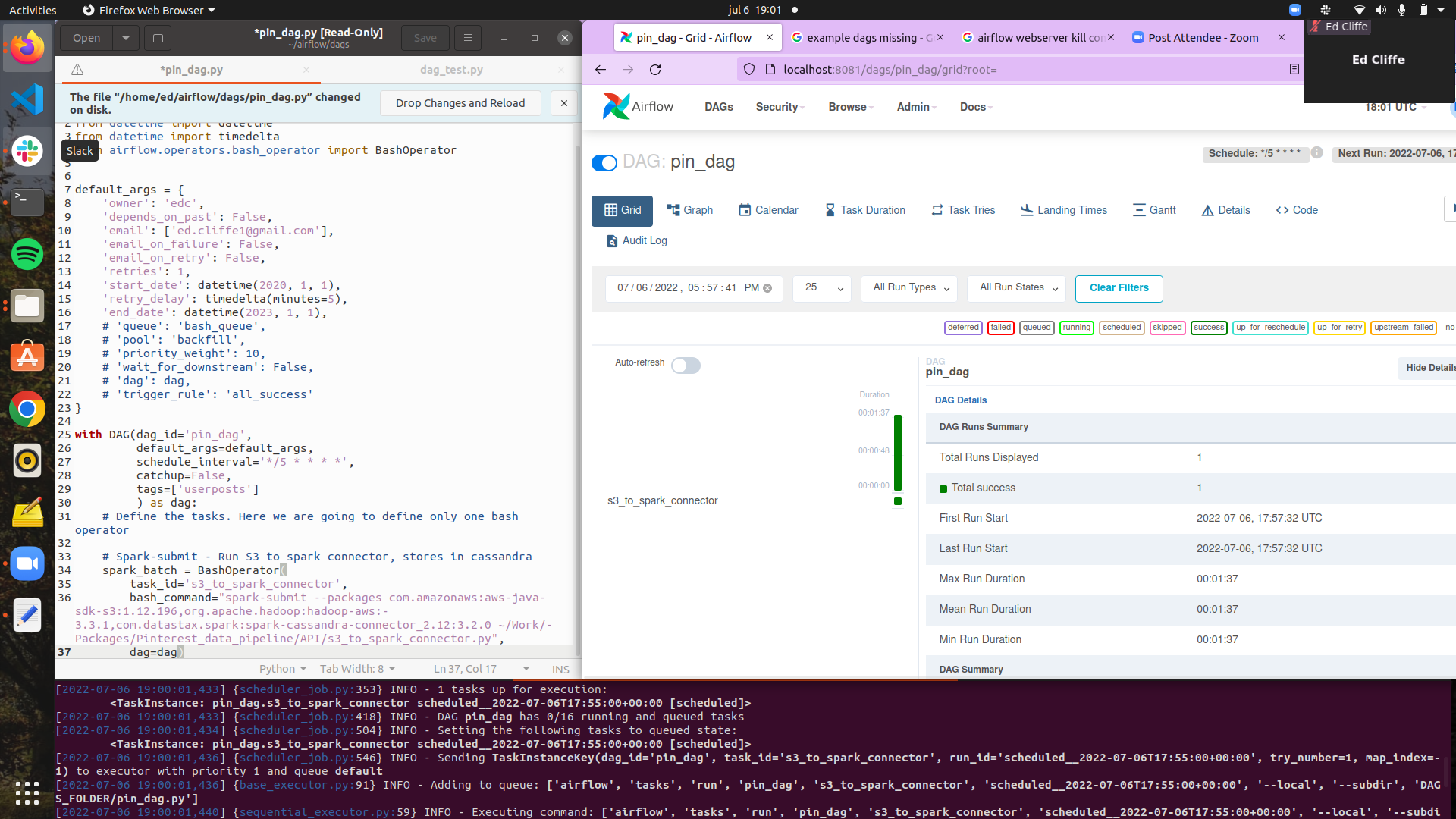{kind=link}
- Prometheus and Grafana are connected to monitor

- The userposts are passed from the kafka topic to pyspark. Basic data processing is applied, and a function is applied, which gives live feedback on whether userposts are the result of errors (containing null values).
- The processed microbatches are then stored in a local postgres database.
- Prometheus and grafana are then used to scrape metrics from postgres, and display dashboards.
