Collects the stats of the top players of each game from https://boardgamearena.com, for each game they have played, and basic information about each game itself.
- Basic Functionality is inherited from the Scraper class defined in bot.py,
- Data cleaning is carried out by cleaning.py.
- The data storage is integrated with cloud services in cloud.py.
- Tests/test_BGA contains the unittest class, which is used to inspect the resulting data after the code is run.
- Due to website updates, the scraper currently uses preloaded links to each game page, rather than freshly scraping them. The player links and their stats will be freshly collected. The limit parameter chooses how many links to access. 2 games takes a couple of minutes, all of them will take about 3.5 hours.
Suggested workflow for scraping the BGA website:
- Check the games limit parameter in BGA_scraper.py, this decides the number of games to scrape.
- Run project/BGA_scraper from inside the project folder
- Run test/test_BGA
Collect the statistics from www.boardgamearena.com for the top 20 players of each game, for the 20 games they have played most.
- Stats: Elo ranking, number of game wins
Also collects basic information and an associated image for each game.
- Tools used : Python, Selenium, BeautifulSoup, SQL,
- Services used: AWS S3, RDS, EC2. Github, Dockerhub, Prometheus, Grafana
The website BoardGameArena was chosen because of the abundance of data available there, and the lack of any public analysis of this data. Potential opportunities include: behavioural analysis of time spent playing, and comparing different high-level player's statistics. For example, are the best players good at one game, or many? Specialised, or generalised?
As a proof of concept, initally I focused on just the basic stats of the top players ranking in their top 20 games.
Which involves:
- Collect the links to all desired games pages from -> https://boardgamearena.com/gamelist?section=all
- Collect the top 20 player links from each game page, along with basic game data and an image for each game. Example page -> https://boardgamearena.com/gamepanel?game=azul
- Visit those links to gather the desired stats. Example Page -> https://boardgamearena.com/player?id=85421235§ion=prestige
- Clean the stats, store in dictionaries and lists
- Run the test suite (tests/test_BGA.py) to check the data is as expected
- Failures sometimes occur just with player lists of some games being unexpected lengths, or a game page without an image. Nothing major.
- Convert dictionaries to dataframes (cloud.py)
- Store in the cloud (cloud.py)
- Run full version of code from EC2 instance, using remote monitoring, connect CI/CD pipeline with Github actions.
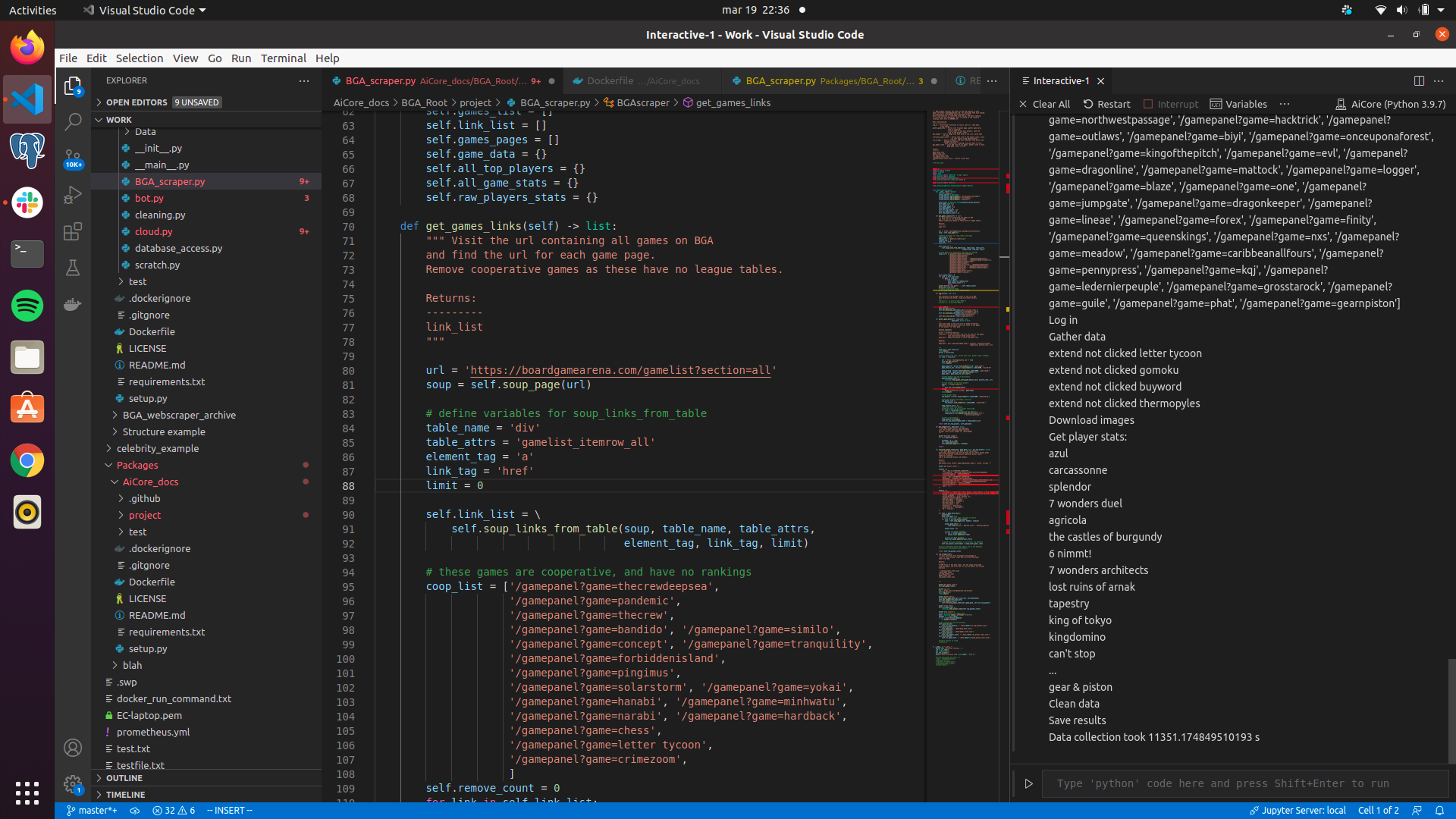
Image showing a full run of the script on the local machine, gathering data from every game on the website, around 450. Making for around 700k data points, taking 11351 seconds (about 3 hours).
https://user-images.githubusercontent.com/94751059/159171546-ed4a5096-e469-4d5b-aa11-6b5e068132d5.png
{kind=link}
This defines some generic scraping tools, which are then inherited by the class defined within BGA_scraper.py for use with boardgamearena.com.
Defining a generic scraper class allows this framework to be more easily adapted for new purposes in the future.
Selenium is used primarily when webpage interaction is required. Methods include sending keys to a web element, clicking a button, and collecting data from the webpage.
BeautifulSoup is used for gathering a whole webpage when there are is no page interaction required. Methods include creating a BS object from the html link, and gathering data from a table from that BS object.
The class BGAscraper inherits many methods from Scraper, in bot.py. It uses these methods to create more complex sequences in order to gather data from BGA. This file does not stand alone, as well as inheriting from Scraper, it relies on cleaning.py and cloud.py
The function run_scraper is of particular importance, as it calls the methods in order to execute the full workflow. Which is as follows:
- 'if name == "main"' block calls run_scraper, along with a timer,
- Gather list of game urls with BeautifulSoup
- Log in using selenium
- Gather tabular data, and save images
- Clean tabular data
- Save results to file, sorted by collection date
Two functions, one to clean the game data. One to clean the raw player stats. Essentially nested string formatting functions which take the useful data from the long strings, and store in dictionies. Clean_games_stats is called once per game as part of a loop in BGA_scraper. Wheras clean_player_stats is built in a nested fashion to clean the whole raw_player_stats file at once.
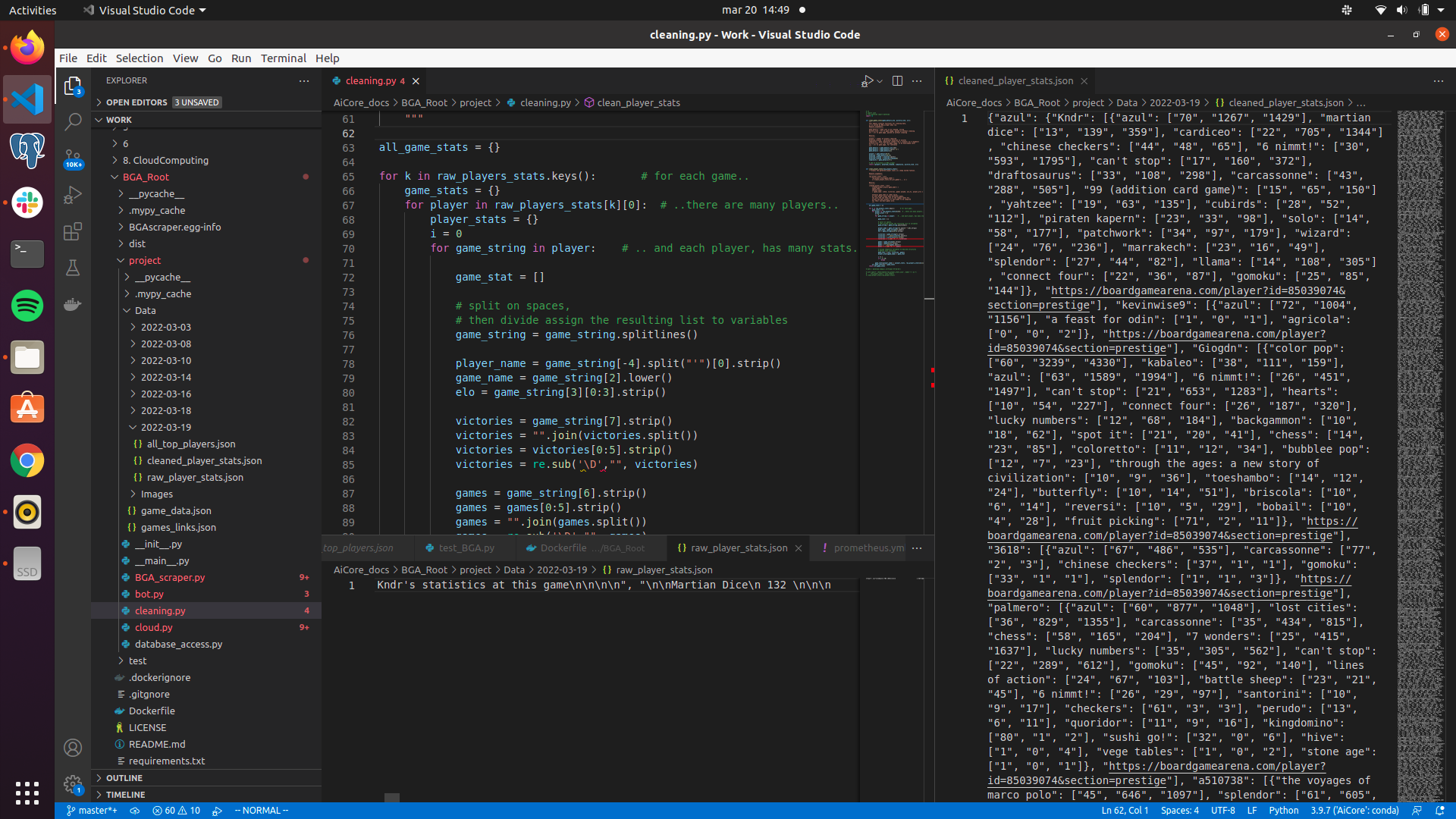
Image showing the raw data (it's one very long line), the code for cleaning, and the resulting cleaned data dictionary.
https://user-images.githubusercontent.com/94751059/159171524-b6fe3c91-4dba-415f-8b17-3e11c30c32d5.png
{kind=link}
Storing the data in the cloud will be essential, as the next step will also run the code in the cloud. This makes it significantly more scalable than when run locally, as more compute and storage can be added on the fly, as needed.
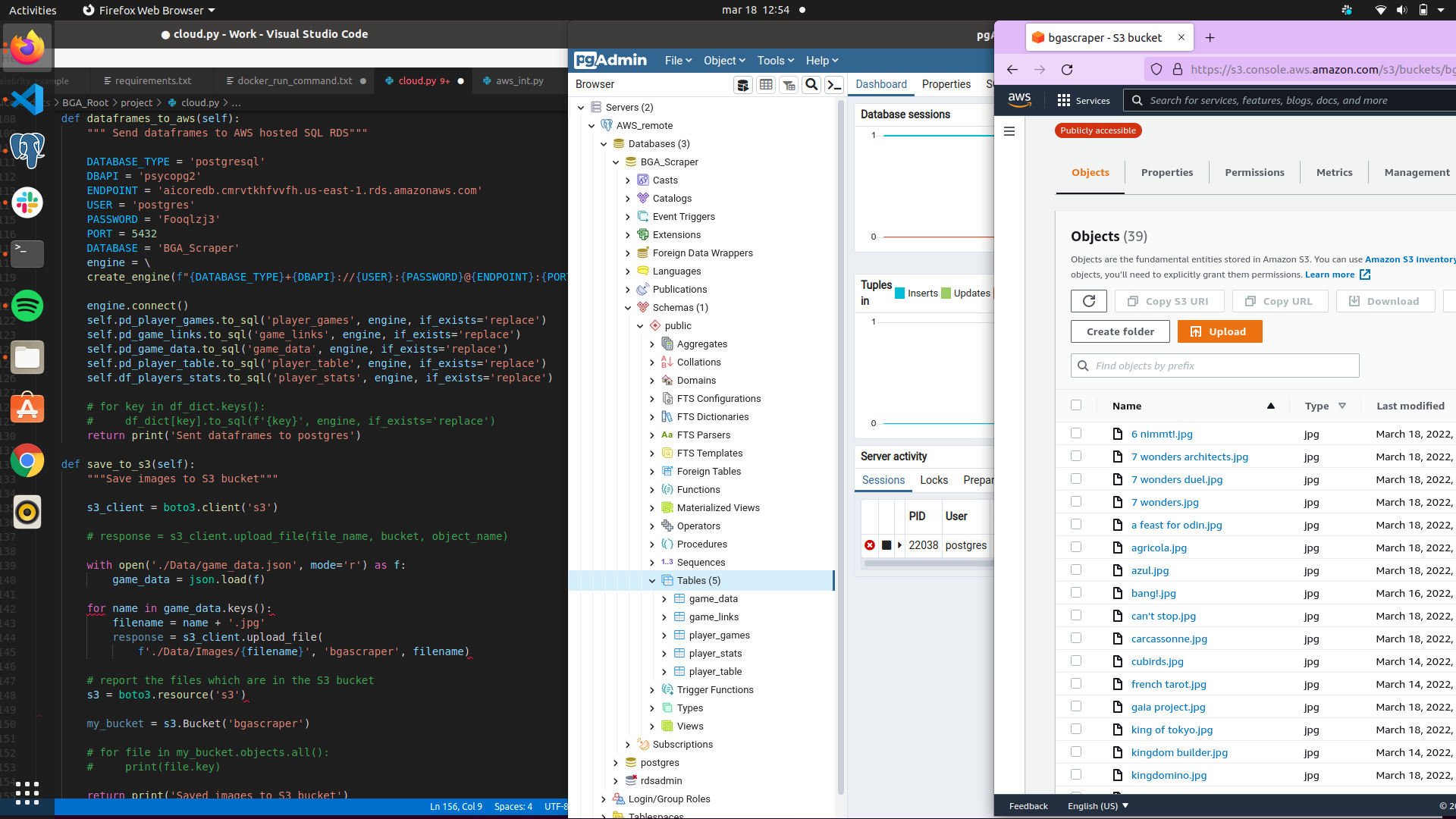
This script takes the data dictionaries and images, converts them to pandas dataframes, and stores using AWS cloud services. Image files are sent to an S3 bucket, whereas the dataframes are stored in RDS. Which is then connected to pgAdmin4.
The player statistics are initially stored in nested dictionaries by BGAscraper. This is not ideal for storing in an RDS database, and so to avoid needing hundreds and thousands of Postgres tables, some reorgansing of the data into fewer, larger tables is required. Although, on later reflection, the nested dictionaries could have been stored as-is in another cloud service, like S3.
Image: cloud.py script, S3 Bucket contents, pgAdmin4 data tables
https://user-images.githubusercontent.com/94751059/159173059-142c9670-747a-42bf-a5e4-66eee2c70691.png
{kind=link}
Potential improvement: organse the data into this dataframe format during original processing, instead of nested dictionaries.
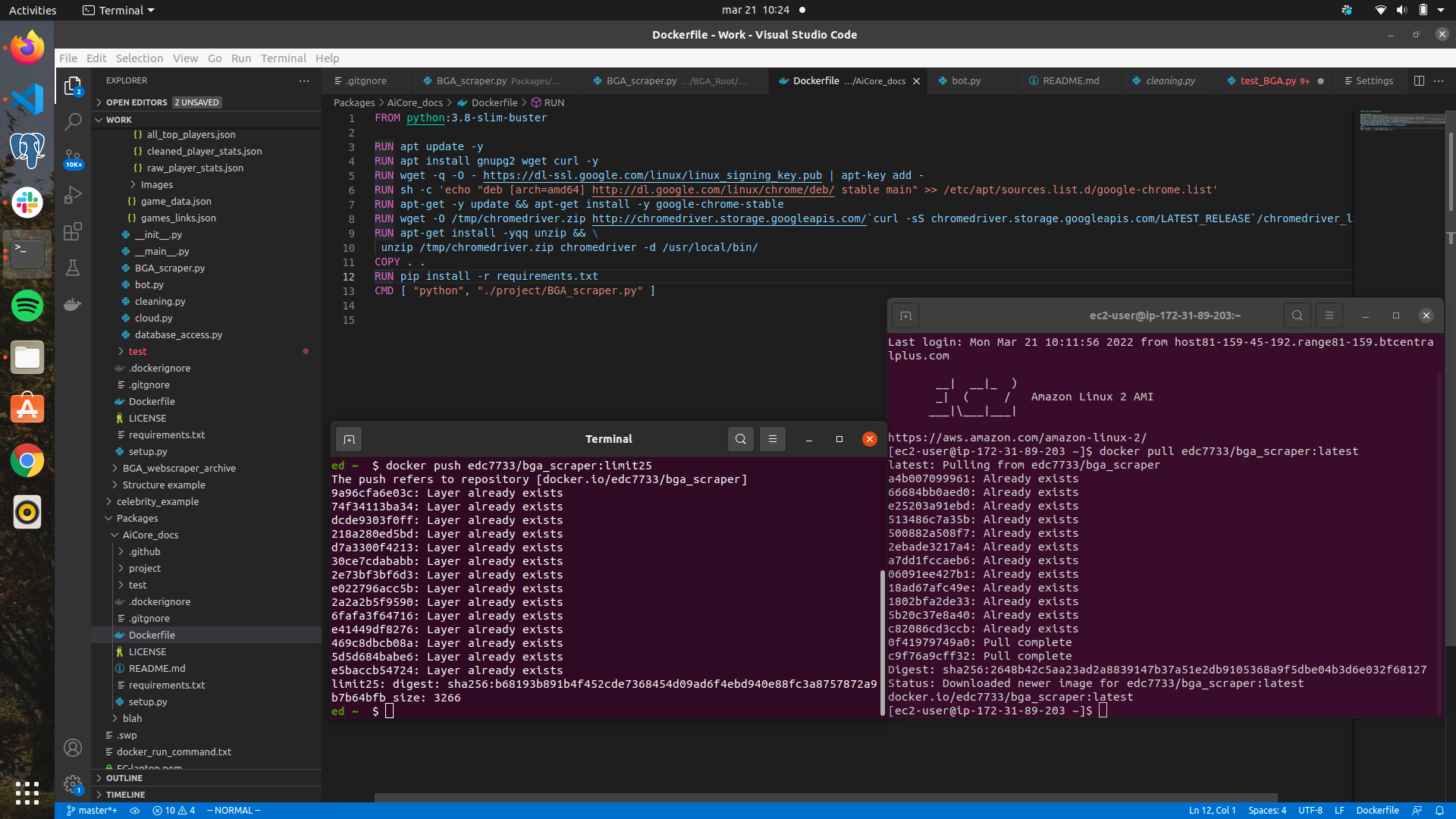
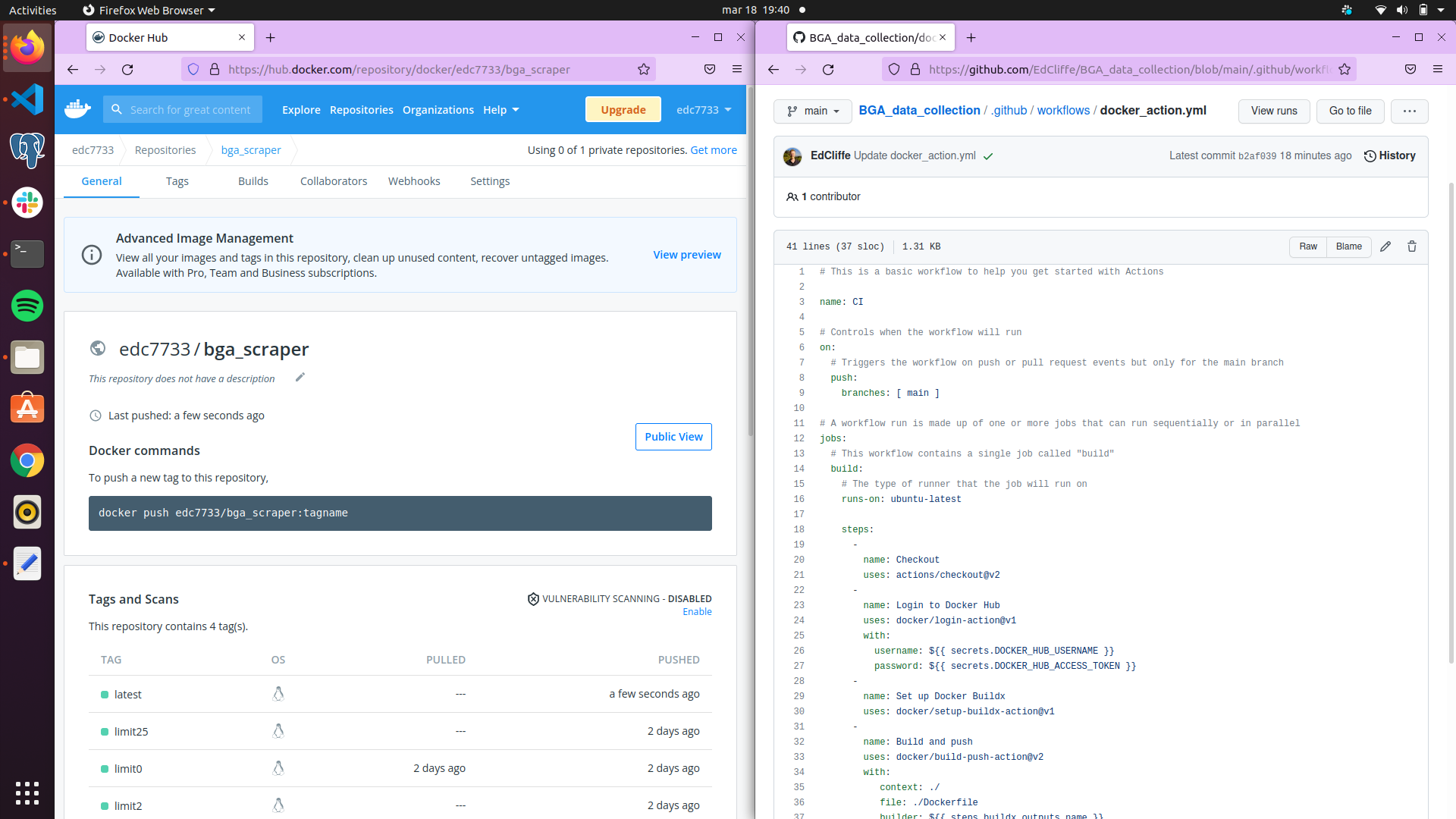
The Docker workflow was used in order to make my script scalably distributable in the cloud. I created a dockerfile to define the dependencies required by my program, and include all necessary files, this creates the docker image. The docker image can then be uploaded to Docker hub, and from there accessed by any machine. In this case, I downloaded the image to my EC2, to run as a container there.
Image: Dockerfile, terminal pushing to dockerhub, and terminal pulling from dockerhub to EC2 https://user-images.githubusercontent.com/94751059/159243019-b7d146d2-3009-45bc-a284-1c4d1e72512d.png
{kind=link}
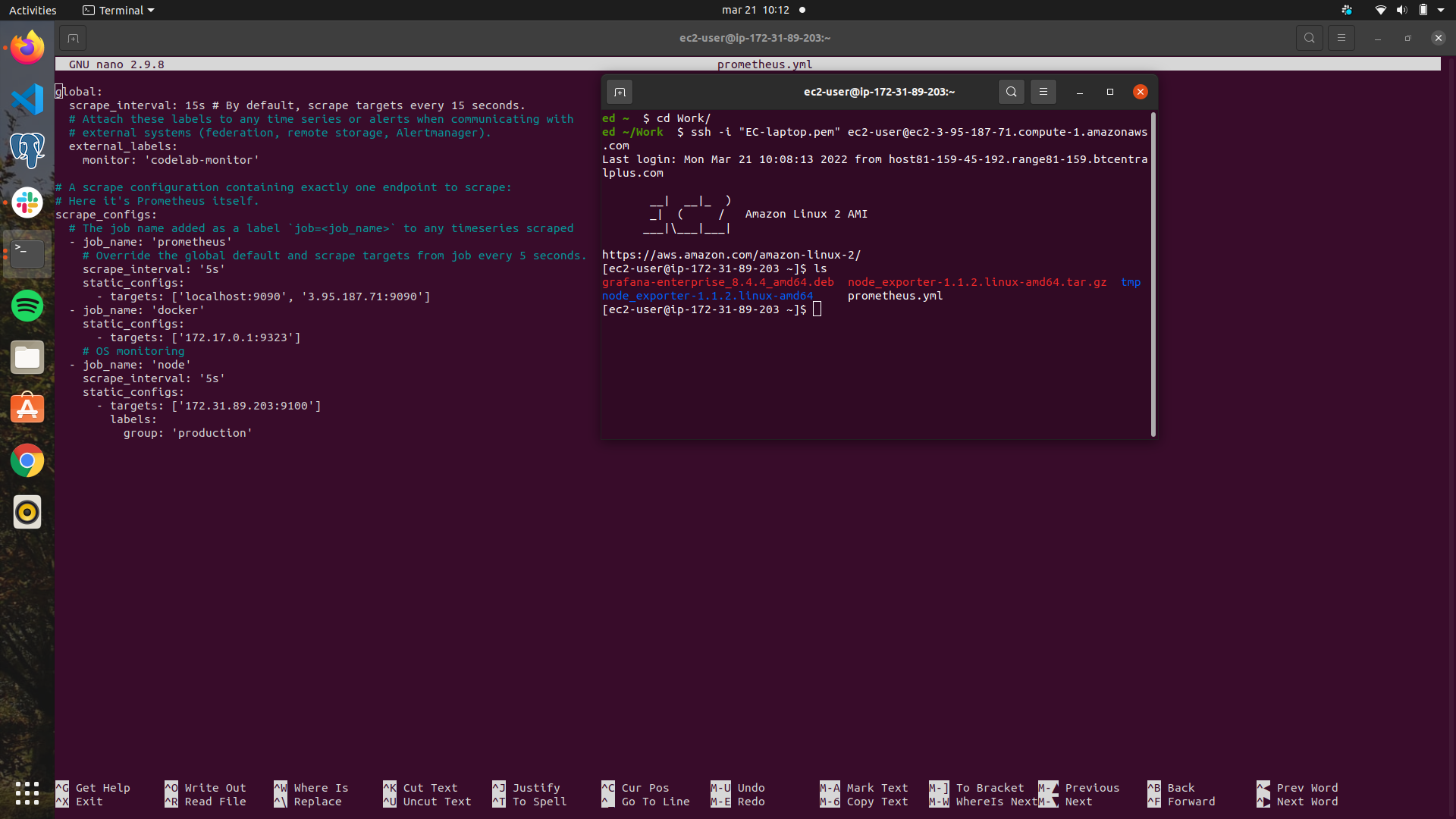
Prometheus allows for metrics from remote services to be viewed on the local machine, so while docker runs the scraper from the EC2, the progress can be monitored. Grafana allows for creation of dashboards for interesting metrics from the data gathered by Prometheus.
Prometheus is run through docker on the EC2, and node exporter installed. The prometheus.yml file defines the settings for scraping the docker metrics on port 9090, and configures to scrape the node_exporter metrics on 9100. Grafana was used to connect to these targets from my local machine. I created a dashboard to monitor docker processes, and OS processes taking place on the EC2 while I ran the Scraper.
Image: prometheus.yml file, and node_exporter https://user-images.githubusercontent.com/94751059/159241224-c3a8338b-5e77-41c9-b1cd-1ee94c597fbe.png
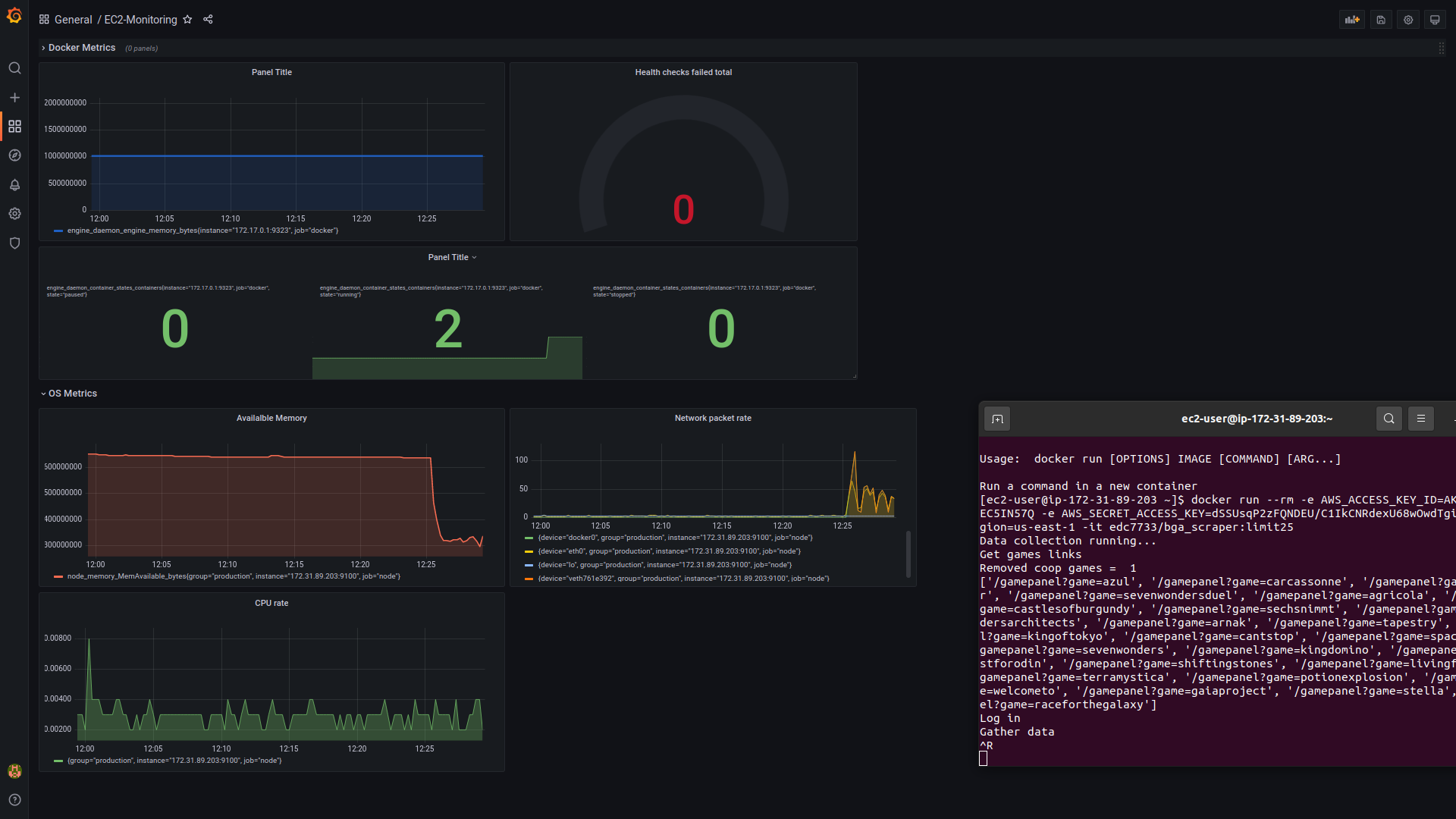
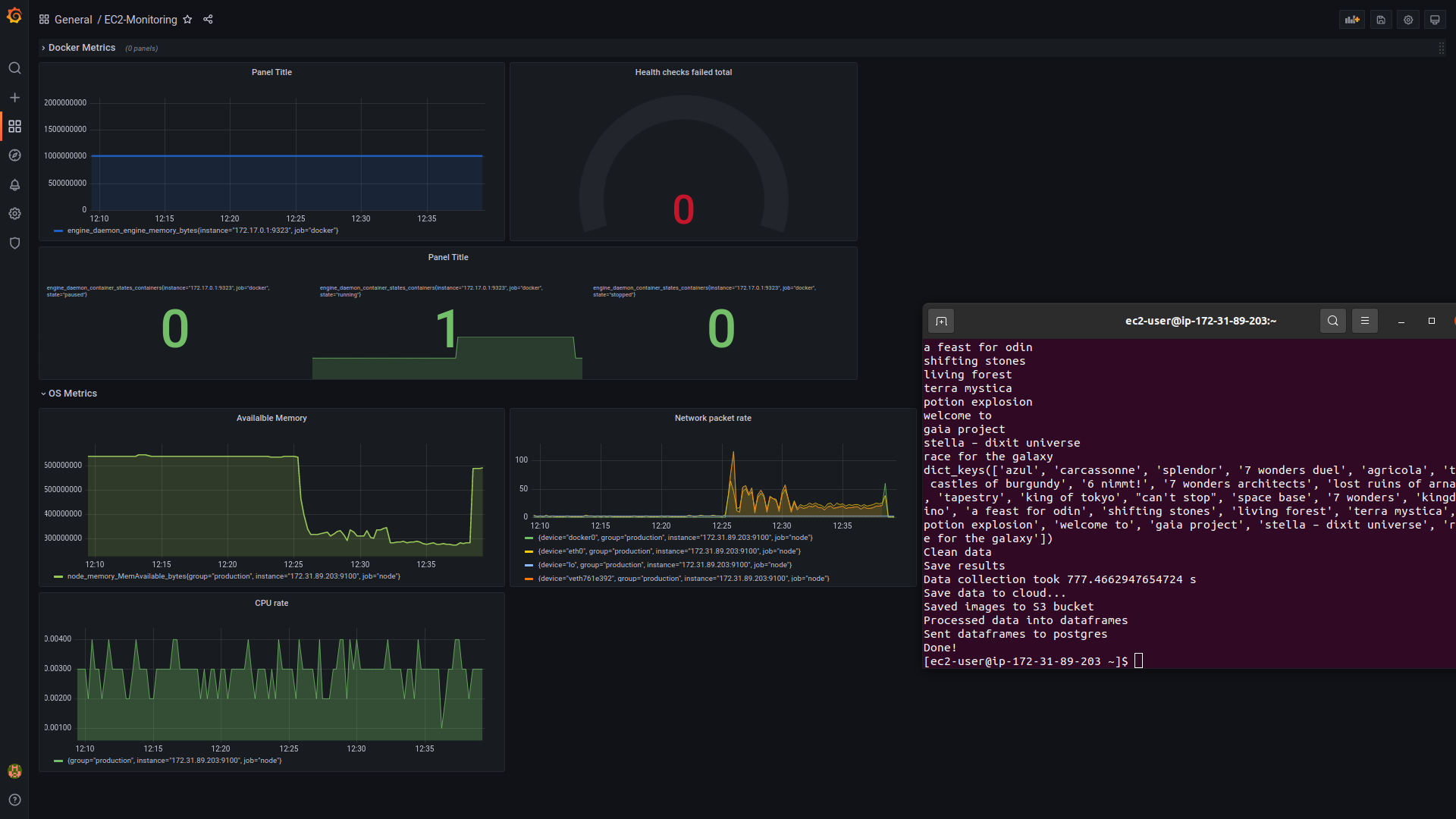
Image: EC2 monitoring with Grafana 1 https://user-images.githubusercontent.com/94751059/159172503-a569a8b2-cac8-48f6-a032-1af05b851f9d.png
Image: EC monitoring with Grafana 2 https://user-images.githubusercontent.com/94751059/159172510-58e6bfe4-aadc-4ca8-8258-b5ab96f0b35e.png
{kind=link}
{kind=link}
{kind=link}
Continuous integration, continuous deployment. These ideas are in service of automating certain areas of the cloud integration pipeline, eg. Unit testing and docker image creation and upload. This automation allows more rapid updating and deployment the code. A basic CI/CD pipeline was produced written in a Github action script. Upon a push to the main branch, a new Docker image was automatically produced and pushed to Docker Hub, using the Docker secret passcodes stored as variables in Github. This will allow greatly streamlined and deployment to the EC2. I can see great possibility for including unit testing with this process.
Image: Github Action -> Docker integration https://user-images.githubusercontent.com/94751059/159172497-52e08563-f145-4abc-b215-8a04382ccdfe.png
{kind=link}
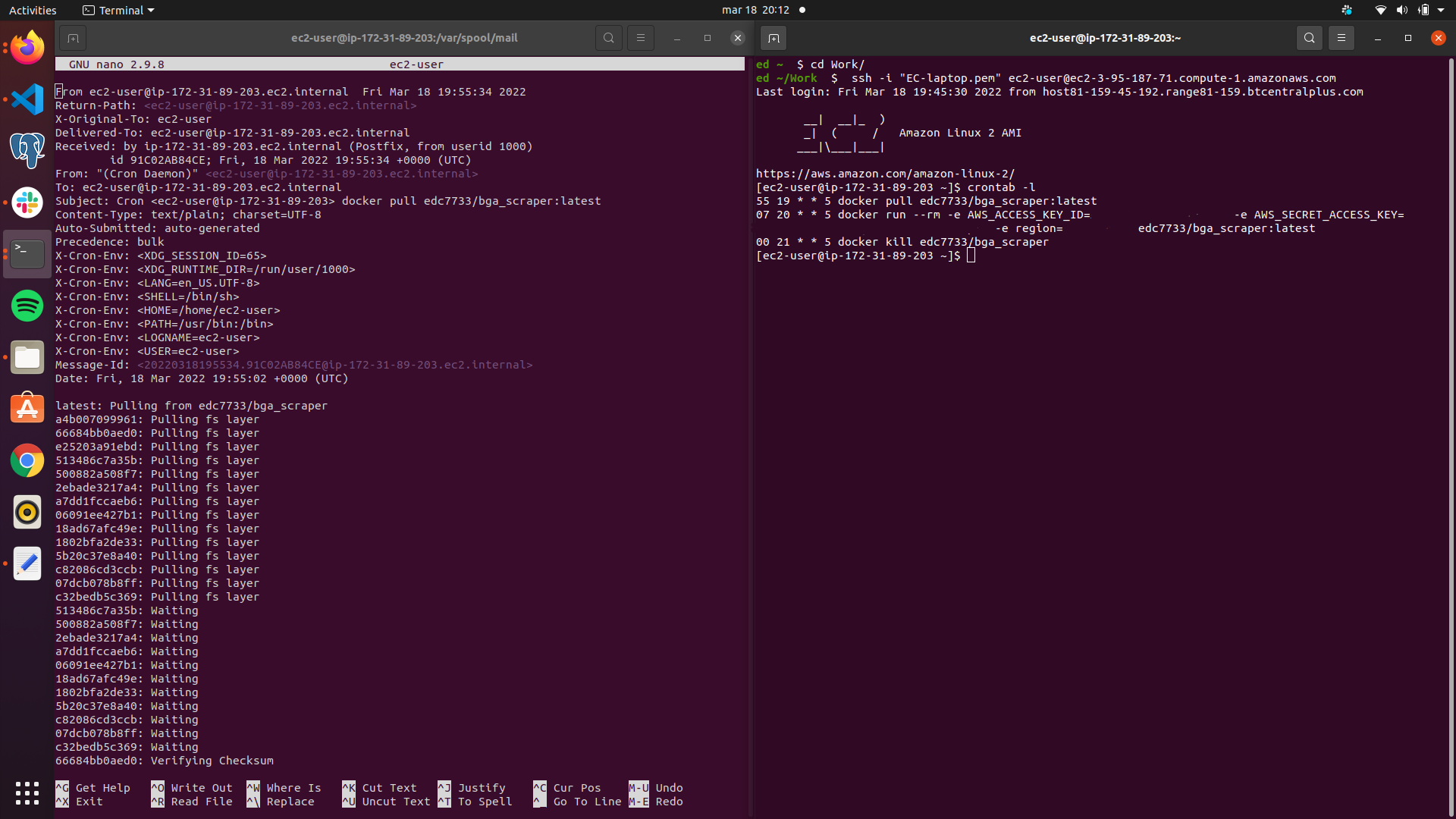
Crontab was used to set up automatic deployment, so the latest docker image would be automatically run once a week.
Image: Crontab job report and crontab script https://user-images.githubusercontent.com/94751059/159173045-86c83a75-8853-4837-be7d-14f3efb71b5a.png
{kind=link}
I have enjoyed this project and deem it a success. I have learned how to gather data from webpages in a fully automated way, and applied this knowledge to one specific use-case for one full life-cycle. I have aggregated a large collection of data, which could now be analysed for (hopefully) meaningful results, and integrated this with cloud data storage, monitoring, and a CI/CD pipeline.
I also see areas of improvement, possible next steps include:
- Store all gathered data in sensible format for storage in RDS during initial data processing, current solution is somewhat limited by the maximum row/column length allowed by pandas dataframes, and implimented as a secondary step, requiring two data processing rounds, which is inefficient. The other option is to store the nested dictionaries in S3 or other NoSQL database as is.
- Split the function into smaller subsections, instead of one huge nested loop for the list of all links. Could gather the games links, split into sub-lists, and run recursively over these smaller lists. This could allow parallel gathering, processing and storing of data, allowing much more scalability and resilience.
- Implementing more exciting OOP concepts, like decorators, abstraction.
- More thorough testing regime if the code is to be taken onto new websites. Testing is very focussed around this particular website and the expected data.
- Including Unit-testing with CI/CD process