Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
// 2.1.1 区间被划分成 [l, mid] 和 [mid + 1, r] intbsearch_1(int l, int r){ while (l < r) { int mid = l + r >> 1; if (check(mid)) r = mid; else l = mid + 1; } return l }
// 2.1.2 区间被划分成 [l, mid - 1] 和 [mid, r] intbsearch_2(int l, int r) { while (l < r) { int mid = l + r + 1 >> 1; if (chedk(mid)) l = mid; else r = mid - 1; } }
# 我的做法:for循环 classSolution: defsumOfSquares(self, nums: List[int]) -> int: n = len(nums) ans = 0 for i inrange(1,n + 1): if n % i == 0: ans += nums[i - 1] * nums[i - 1] return ans
-
-
1 2 3 4 5 6 7 8 9 10
# 参考榜单:enumerate做法 classSolution: defsumOfSquares(self, nums: List[int]) -> int: n = len(nums) ans = 0 for k, v inenumerate(nums, 1): # key 是从 1 开始的 if n % k: continue ans += v * v return ans
classSolution: defmaximumBeauty(self, nums: List[int], k: int) -> int: nums.sort() ans = 1 for i, v inenumerate(nums): j = bisect_right(nums, v + 2 * k) ans = max(ans, j - i) return ans
# 我的方法:很笨,考虑两个条件,区间长度和前n-1项是否为自然数序列,这个方法由于一开始没有考虑前者,所以wa了一次。 classSolution: defisGood(self, nums: List[int]) -> bool: n = len(nums) nums.sort() if n - 1 != nums[-1]: returnFalse for i inrange(1, n - 1): if i != nums[i - 1]: print([i, nums[i]]) returnFalse returnTrue
# 我的方法 classSolution: defsortVowels(self, s: str) -> str: # print((ord('a'), ord('A'))) # print([ord('e'), ord('i'), ord('o'), ord('u')]) n = len(s) cnt = [] for i inrange(n): if s[i] == 'a'or s[i] == 'e'or s[i] == 'i'or s[i] == 'o'or s[i] == 'u'or s[i] == 'A'or s[i] == 'E'or s[i] == 'I'or s[i] == 'O'or s[i] == 'U': cnt.append(s[i]) cnt.sort() t = "" x = 0 for c in s: if c == 'a'or c == 'e'or c == 'i'or c == 'o'or c == 'u'or c == 'A'or c == 'E'or c == 'I'or c == 'O'or c == 'U': t += cnt[x] x += 1 else: t += c return t
# 我的解法:做了一个split()分割,再来个循环遍历split处理后的字符串,遇到字符串则不输出。 classSolution: defsplitWordsBySeparator(self, words: List[str], separator: str) -> List[str]: ans = [] ans1 = [] for i in words: ans += i.split(separator) n = len(ans) for i inrange(n): if ans[i] != "": ans1.append(ans[i]) return ans1
$ git pull remote: remote: ======================================================================== remote: remote: Your SSH key has expired. remote: remote: ======================================================================== remote: fatal: Could not read from remote repository.
Please make sure you have the correct access rights and the repository exists.
import torch from torch.utils.data import Dataset from torchvision import datasets from torchvision.transforms import ToTensor import matplotlib.pyplot as plt
下面距离一个最简单的单层神经网络,其中包含输入 x、参数 w 和 b,以及一些损失函数。可以在 PyTorch 中按以下方式定义它:
1 2 3 4 5 6 7 8
import torch
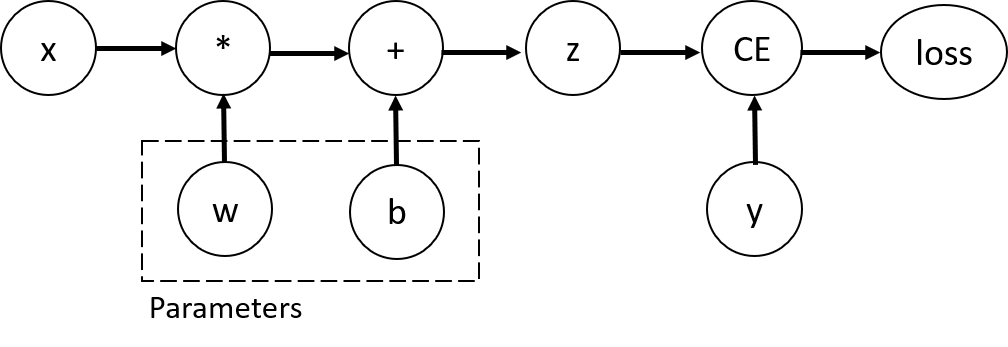
x = torch.ones(5) # input tensor y = torch.zeros(3) # expected output w = torch.randn(5, 3, requires_grad = True) b = torch.randn(3, requires_grad = True) z = torch.matmul(x, w) + b loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
用来构造计算图的函数实际上是类 Function 的对象。该对象指导如何计算正向函数,以及如何在反向传播步骤中计算其导数。对向后传播函数的引起存储在张量的属性中的 grad_fn。您可以在PyTorch的官方文档中找到更多信息 Function。
1 2
print(f"Gradient function for z = {z.grad_fn}") print(f"Gradient function for loss = {loss.grad_fn}")
打印输出:
1 2
Gradient function for z = <AddBackward0 object at 0x7d800ac85840> Gradient function for loss = <BinaryCrossEntropyWithLogitsBackward0 object at 0x7d800ac85ea0>
梯度计算
为了优化神经网络中的参数权重,我们需要计算损失函数相对于参数的导数,即我们需要在固定 x 和 y 值的情况下,求出 $\frac{\partial loss}{\partial w}$ 和 $\frac{\partial loss}{\partial b}$。
# 我的方法:很笨,考虑两个条件,区间长度和前n-1项是否为自然数序列,这个方法由于一开始没有考虑前者,所以wa了一次。 classSolution: defisGood(self, nums: List[int]) -> bool: n = len(nums) nums.sort() if n - 1 != nums[-1]: returnFalse for i inrange(1, n - 1): if i != nums[i - 1]: print([i, nums[i]]) returnFalse returnTrue
# 我的方法 classSolution: defsortVowels(self, s: str) -> str: # print((ord('a'), ord('A'))) # print([ord('e'), ord('i'), ord('o'), ord('u')]) n = len(s) cnt = [] for i inrange(n): if s[i] == 'a'or s[i] == 'e'or s[i] == 'i'or s[i] == 'o'or s[i] == 'u'or s[i] == 'A'or s[i] == 'E'or s[i] == 'I'or s[i] == 'O'or s[i] == 'U': cnt.append(s[i]) cnt.sort() t = "" x = 0 for c in s: if c == 'a'or c == 'e'or c == 'i'or c == 'o'or c == 'u'or c == 'A'or c == 'E'or c == 'I'or c == 'O'or c == 'U': t += cnt[x] x += 1 else: t += c return t
# 我的解法:做了一个split()分割,再来个循环遍历split处理后的字符串,遇到字符串则不输出。 classSolution: defsplitWordsBySeparator(self, words: List[str], separator: str) -> List[str]: ans = [] ans1 = [] for i in words: ans += i.split(separator) n = len(ans) for i inrange(n): if ans[i] != "": ans1.append(ans[i]) return ans1
# 我的做法:for循环 classSolution: defsumOfSquares(self, nums: List[int]) -> int: n = len(nums) ans = 0 for i inrange(1,n + 1): if n % i == 0: ans += nums[i - 1] * nums[i - 1] return ans
1 2 3 4 5 6 7 8 9 10
# 参考榜单:enumerate做法 classSolution: defsumOfSquares(self, nums: List[int]) -> int: n = len(nums) ans = 0 for k, v inenumerate(nums, 1): # key 是从 1 开始的 if n % k: continue ans += v * v return ans
classSolution: defmaximumBeauty(self, nums: List[int], k: int) -> int: nums.sort() ans = 1 for i, v inenumerate(nums): j = bisect_right(nums, v + 2 * k) ans = max(ans, j - i) return ans
// 2.1.1 区间被划分成 [l, mid] 和 [mid + 1, r] intbsearch_1(int l, int r){ while (l < r) { int mid = l + r >> 1; if (check(mid)) r = mid; else l = mid + 1; } return l }
// 2.1.2 区间被划分成 [l, mid - 1] 和 [mid, r] intbsearch_2(int l, int r) { while (l < r) { int mid = l + r + 1 >> 1; if (chedk(mid)) l = mid; else r = mid - 1; } }
// 2.1.1 区间被划分成 [l, mid] 和 [mid + 1, r] intbsearch_1(int l, int r){ while (l < r) { int mid = l + r >> 1; if (check(mid)) r = mid; else l = mid + 1; } return l }
// 2.1.2 区间被划分成 [l, mid - 1] 和 [mid, r] intbsearch_2(int l, int r) { while (l < r) { int mid = l + r + 1 >> 1; if (chedk(mid)) l = mid; else r = mid - 1; } }
# 二分查找 defcheck(x): # 判断x是否满足某种性质 if x > 0: returnTrue else: returnFalse
# 2.1.1 区间被划分成 [l, mid] 和 [mid + 1, r] defbsearch_2(l, r): while l < r: mid = l + r >> 1 if (check(mid)): r = mid else: l = mid + 1 return l
# 2.1.2 区间被划分成 [l, mid - 1] 和 [mid, r] defbsearch_1(l, r): while l < r: mid = l + r + 1 >> 1 if (check(mid)): l = mid else: r = mid - 1 return l
浮点数二分
只有C++要考虑,高贵的Python不需要考虑。
1 2 3 4 5 6 7 8 9 10 11
#include<iostream>
doublebsearch_3(double l, double r){ constdouble eps = 1e-6; while (r - l > eps) { double mid = (l + r) / 2; if (check(mid)) r = mid; else l = mid; } return l; }
]]>
+ Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
 -
-
-
-
-
-
-
-