Releases: hasura/graphql-engine
2nd beta release for 1.1.0
Known Issues
Instructions to downgrade from v1.1.0-beta.2 to v1.0.0: #3822 (comment)
- Returning null valued references objects throws internal error: #3754
- Event Trigger functions are not getting recreated after update/reload operations: (#3784, #3803)
- Enums are not getting updated: #3759
Changelog
1st beta release for 1.1.0
Known Issues
Instructions to downgrade from v1.1.0-beta.1 to v1.0.0 : #3710 (comment)
- Missing
hdb_viewwhen inserting (#3710, #3598) - There is a bug in the CLI auto-update code which will cause the CLI to NOT auto-update to this version. If you have the server running on
v1.1.0-beta.1release and want to use the CLI, please download/install the CLI again rather than auto-updating. (#3706, #3709) - Returning null valued references objects throws internal error: #3754
- Event Trigger functions are not getting recreated after update/reload operations: (#3784, #3803)
- Enums are not getting updated: #3759
Changelog
A more detailed changelog will be added soon.
- server: check db connection in healthz endpoint (close #2645) (#3440)
- server: fix updating a column with multiple operators causing postgres query error (fix #3432) (#3458)
- server: read cache control header to refresh JWK (fix #3301) (#3446)
- server: bulk query should not care about access mode of select or count queries (#3467)
- server: Update server/CONTRIBUTING.md and include manual build/test steps (#3472)
- server: fix insert permission views are not unique for long role names (fix #3444) (#3486)
- server: avoid CTE expressions in sql function queries, close #3349 (#3504)
- server: fix json/jsonb columns as String values in nested returning of a mutation (fix #3365) (#3375)
- server: fix resolving user info in websocket transport (#3509)
- server: Fix documentation of HASURA_GRAPHQL_PG_CONNECTIONS (#3495)
- server: export metadata without nulls, empty arrays & default values (#3393)
- server: Allow request body to be logged even with successful queries (#3529)
- server: Test with postgis 3.0.0 (#3519)
- server: Support batched queries (fix #1812) (#3490)
- server: Fix unnecessary conditional logic in cache implementations
- server: Fix Hasura.Cache.Bounded.mkCacheSize to make sure we don't silently wrap or accept 0
- server: Initial benchmarks for caching. Closes #3530
- server: Show request id on test failures (#3556)
- server: fix absence of "args" input field omits session variable argument, fix #3576 (#3585)
- server: Report errors in parallel when batching (#3605)
- server: add query execution time and response size to ws-server logs in websocket transport (#3584)
- server: Add Hasura.Incremental, a library for incremental builds
- server: Refactor schema cache construction to avoid imperative updates
- server: Use arrows instead of monads to define the schema cache construction
- server: Split up Hasura.RQL.DDL.Schema.Cache
- server: Use a significantly more efficient table_info_agg view
- server: Switch to a CPS implementation of Rule
- server: Add caching for recreating event trigger functions
- server: Properly check that custom field names do not conflict with other fields
- server: Fix new hdb_table_info_agg query to fetch column base types
- server: Move arrow transformers into a separate module
- server: Add support for fine-grained dependency tracking to Incremental
- server: Use fine(er)-grained dependency tracking when building permissions
- server: Alter the type of hdb_catalog columns that reference SQL identifiers
- server: Add missing check in SetTableCustomFields; update various test cases
- server: incremental metadata: Clean up a few lingering loose ends
- server: remove brotli from packaging and CI images (#3673)
- server: include scalars types returning by computed fields in generated schema (fix #3650) (#3651)
- server: add computed fields support on console (close #3203 #3565) (#3522)
- server: fix cache-control header parsing for JWK (fix #3655) (#3676)
- server: Add fast path for server internal metadata migrations (#3686)
- cli: fix(cli): mark from flag as required for squash (close #3400) (#3500)
- cli: add examples to all cli commands (#3475) (#3492)
- cli: cli(installer): add -f flag to curl (fix #1871) (#3477)
- cli: cli(build): migrate to go modules (close #3476) (#3493)
- cli: export metadata without nulls, empty arrays & default values (#3393)
- cli: Fix failing CLI test (#3567)
- cli: console(fix): blank image on remote schemas section (close #220… (#3574)
- cli: cli: add directory name as an argument to init cmd (#3590)
- cli: cli: add commands to manage inconsistent metadata (close #2766) (#2973)
- cli: cli: use json logs on non-terminal envs (close #2770) (#3528)
- cli: cli(fix): squash command not adding the last down (close #3401) (#3569)
- cli: cli(fix): better error handling on non-json api responses (clos… (#3104)
- cli: cli(fix): execute down migration in the correct order (#3625)
- cli: cli: add browser flag to console command (close #3333) (#3601)
- cli: cli: update go-binddata, fix realize (close #3588) (#3687)
- cli: update manifests to v1.1.0-beta.1
- console: add read_only flag to run_sql select queries from console (#3465)
- console: fix column edit migrations (close #3291) (#3441)
- console: add custom root fields section for views to console (#3532)
- console: remove console feature version checks (#3494)
- console: merge branch 'release-v1.0' to master after stable release
- console: console: Bump dependencies to support Node v13.x (#3579)
- console: add base code for console read only mode (#3466)
- console: display postgres version in About page of console (close #3461) (#3611)
- console: misc console improvements (#3435)
- console: console: add hasura pro info button (#3594)
- console: update console pro popup content (#3660)
- console: Use fine(er)-grained dependency tracking when building permissions
- console: add bigint id to frequently used columns (close #3524) (#3669)
- console: run sql queries refactor (close #3543) (#3662)
- console: add computed fields support on console (close #3203 #3565) (#3522)
- console: update console readme (#3691)
v1.0.0
Changelog
1st stable release for Hasura (v1.0.0) is here 🎉 🎂 👏
This is just a promotion of v1.0.0-rc.1 with a small bugfix on console (fix feature compatibility version check expression (#3546))
Release process
Some notes on how new releases will be made are detailed below:
- Hasura releases will follow semver.
- Updates to any 1.x version will be non-breaking.
- A beta release channel in the community Discord server for developers to try out the next version in dev/staging and report issues.
- Every release will be promoting the beta/release-candidate(rc) release to a stable release and the creation of a new beta release for the next version.
v1.0.0-rc.1
Changelog
Accessing session information in functions
Functions can now access session information (JSON) when they are tracked via version 2 of the track_function metadata API (which allows specifying an input arg to access session information).
Example
Tracking a function and specifying the input arg:
POST /v1/query HTTP/1.1
Content-Type: application/json
X-Hasura-Role: admin
{
"type": "track_function",
"version": 2,
"args": {
"function": {
"schema": "public",
"name": "search_articles"
},
"configuration": {
"session_argument": "hasura_session"
}
}
}Here's how you can access session information in function:
-- A simple function which accesses role
-- information from the 'hasura_session' argument
CREATE FUNCTION search_articles(hasura_session json)
RETURNS SETOF articles AS $$
SELECT * FROM articles where author_id = (hasura_session ->> 'x-hasura-user-id')
$$ LANGUAGE sql STABLE;Performance (#3012)
Configure GraphQL engine's internal operations cache size
The size of the operations plan cache used by GraphQL engine can now be limited. To keep the cache size constant, the older entries are discarded using LRU strategy.
Cache size (number of operations) can be configured through the command line argument --query-plan-cache-size and the env variable QUERY_PLAN_CACHE_SIZE (the numbers of GraphQL operations to be cached; 100 is a decent default value for most apps). The accepted values are from 0-65535 (0 disables the cache). When this value isn't specified, an unbounded cache is used which is the current behaviour. A future iteration of this change will change this behavious to default to a fixed cache size.
read-only run_sql API
A read_only parameter has been added to the run_sql metadata API. This sets the postgres transaction mode to ReadOnly. This can be used by the console, etc. to perform select operations without forcing cache/gctx recomputation.
Other server & CLI changes
- Minor server changes (#3154, #3414, #3439)
- Hasura Tests (#3356,#3434)
- Add identifier to
migrate statuscommand's response in CLI (close #2376) (#3109)
Console changes
v1.0.0-beta.10
Changelog
Events subsystem
Improves the query to fetch new events. This should significantly reduce the baseline load on PG.
Events of deleted triggers will be archived (but not deleted). This means if a new trigger is created with the same name, it won't show the archived events in console. (#3236)
WARNING: Might take long time during catalog update because an index is created over the events.
Remote schemas
Adds X-Forwarded-Host and X-Forwarded-User-Agent (original User-Agent) headers to the request made to a remote GraphQL server. (close #2572) (#3347)
Ordered metadata export
The exported metadata from server is now ordered in a deterministic fashion. This should help in reducing merge conflicts if you're managing this file manually and if many develepers are working on it independently. (close #3125) (#3230)
Bug fixes
- The exported metadata now contains computed fields too (#3211)
- Nested inserts with relationships in returning clause on tables with array columns doesn't throw and error (#3198)
- Table configuration defaults are now properly handled on the console (#3317)
- Console now shows only tracked tables while creating an event trigger (#3227)
See this page for a commit-wise changelog.
v1.0.0-beta.9
Changelog
Upgrading & downgrading
-
You can upgrade to
beta.9from any version. -
You can downgrade to
beta.8just by changing the docker image tag. -
For downgrading to other versions, you may need to manually run SQL scripts if your downgrade path involves a catalog change. Please see this for catalog history.
Read more about upgrading and downgrading.
Updates to CLI & Migrations
New migrations folder structure
Starting with this release, Hasura CLI supports a new directory structure for migrations folder and defaults to that for all new migrations created.
Each migration will get a new directory with the name format timestamp_name and inside the directory, there will be four files:
└── migrations
├── 1572237730898_squashed
│ ├── up.sql
│ ├── up.yaml
│ ├── down.yaml
│ └── down.sqlExisting files old migration format timestamp_name.up|down.yaml|sql will continue to work alongside new migration files.
Squash command
Lots of users have expressed their interest in squashing migrations (see #2724 and #2254) and some even built their own tools to do squash. In this PR, we take a systematic approach to squash migrations.
A new command called migrate squash is introduced. Note that this command is in PREVIEW and the correctness of squashed migration is not guaranteed (especially for down migrations). From our tests, it works for most use cases, but we have found some issues with squashing all the down migrations, partly because the console doesn't generate down migrations for all actions.
Hence, until we add an extensive test suite for squashing, we'll keep the command in preview. We recommend you to confirm the correctness yourself by diffing the SQL and Metadata before and after applying the squashed migrations (we're also thinking about embedding some checks into the command itself).
$ hasura migrate squash --help
(PREVIEW) Squash multiple migrations leading upto the latest one into a single migration file
Usage:
hasura migrate squash [flags]
Examples:
# NOTE: This command is in PREVIEW, correctness is not guaranteed and the usage may change.
# squash all migrations from version 1572238297262 to the latest one:
hasura migrate squash --from 1572238297262
Flags:
--from uint start squashing form this version
--name string name for the new squashed migration (default "squashed")
--delete-source delete the source files after squashing without any confirmationUsage:
# squash all migrations from version 1572238297262 to the latest one:
hasura migrate squash --from 1572238297262
# mark the squashed one as applied
hasura migrate apply --version 1572238297262 --skip-executionSee #3072 for more details.
Dry run and diff metadata
A new command. metadata diff is introduced (in PREVIEW) to show comparisons between two different sets of Hasura metadata.
# Show changes between server metadata and the exported metadata file:
hasura metadata diff
# Show changes between server metadata and that in local_metadata.yaml:
hasura metadata diff local_metadata.yaml
# Show changes between metadata from metadata.yaml and metadata_old.yaml:
hasura metadata diff metadata.yaml metadata_old.yaml
This release also adds a --dry-run flag to metadata apply command which will print the diff and exit rather than actually applying the metadata.
This is just a general-purpose diff. A more contextual diff with the understanding of metadata will be added later.
Support for Postgres 12
-
Postgres 12 is now officially supported and all our tests are run against 12.0 also
-
pg_dumpbinary bundled with the Docker image is updated to 12
Docs
- AWS Cognito JWT Guide (#2910)
- Production checklist (close #2561) (#3140)
Other changes
v1.0.0-beta.8
Changelog
Note: This release fixes the bugs with beta.7 and this is a combined changelog since beta.6.
Upgrading & downgrading
-
You can upgrade to
beta.8from any version. -
Downgrading: You may need to manually run SQL scripts if your downgrade path involves a catalog change. Please see this for catalog history.
Read more about upgrading and downgrading.
Table of contents 🗂
-
Customize names of root fields and column fields
-
Computed fields
-
Create permissions with conditions spanning tables
-
Performance optimisations
- Compress HTTP responses
- Optmization for all subscriptions
-
Annotate GraphQL schema for better documentation
-
Update conditionally when using upsert
-
Better support for Postgres connection string parameters
-
Docs
-
Others
Customize the names of root fields and column fields 🏷
This change allows customizing the names of root fields and the column fields in Hasura's GraphQL schema.
E.g. the default root field names generated for a table named author are:
Queries/Subscriptions:
authorauthor_by_pkauthor_aggregate
Mutations:
insert_authordelete_authorupdate_author
The above and the names of the column fields can now be customized.
How to customize
Console
(to be available shortly)
-
Customizing root fields names: Head to the
Modifytab of the table whose generated root fields you want to change: -
Customizing column field names: Head to the
Modifytab of the table whose column fields you want to alias and edit the column for an option to provide a custom name:


Metadata API
The v2 track_table allows you to specify all the customizations while tracking a table. Here's an example request:
POST /v1/query HTTP/1.1
Content-Type: application/json
X-Hasura-Role: admin
{
"type": "track_table",
"version": 2,
"args": {
"table": "authors",
"configuration": {
"custom_root_fields": {
"select": "authors",
"select_by_pk": "author",
"select_aggregate": "authorStats",
"insert": "createAuthors",
"update": "updateAuthors",
"delete": "removeAuthors"
},
"custom_column_names": {
"id": "authorId"
}
}
}
}For tables that have already been tracked, you can use the set_table_custom_fields metadata API:
POST /v1/query HTTP/1.1
Content-Type: application/json
X-Hasura-Role: admin
{
"type": "set_table_custom_fields",
"version": 2,
"args": {
"table": {
"name": "site_employees",
"schema": "rocc"
},
"custom_root_fields": {
"select": "authors",
"select_by_pk": "author",
"select_aggregate": "authorStats",
"insert": "createAuthors",
"update": "updateAuthors",
"delete": "removeAuthors"
},
"custom_column_names": {
"id": "authorId"
}
}
}- The original Postgres table and column names are used in metadata definitions for relationships, permissions etc.
- Please ensure that your client apps are in sync with this change as once you begin using custom names, requests with the original field names will result in an error.
- Known limitations: an error is thrown if the custom name and the original name of a column are the same. This is being fixed in #3154.
Computed fields
Computed fields are virtual values or objects that are dynamically computed and can be queried along with a table's columns. Computed fields are computed when requested for via SQL functions using other columns of the table and other custom inputs if needed. See pull request description.
Adding a computed field
Computed fields are added to a table via SQL functions. Any SQL function which accepts table row type as one of the input arguments, returns base types (integer, Text, etc.) or SETOF <table-name> and not VOLATILE can be added as computed field.
Example:-
Let's say we have a table, author, that has two text columns, first_name and last_name, and we want to enrich the table with a virtual field that combines these columns into a new one, full_name. We can do this by adding a computed field:
-
Define a SQL function called
author_full_name:CREATE FUNCTION author_full_name(author_row author) RETURNS TEXT AS $$ SELECT author_row.first_name || ' ' || author_row.last_name $$ LANGUAGE sql STABLE;
-
Add a computed field,
full_nameto theauthortable with the SQL function above using the following API.POST /v1/query HTTP/1.1 Content-Type: application/json X-Hasura-Role: admin { "type":"add_computed_field", "args":{ "table":{ "name":"author", "schema":"public" }, "name":"full_name", "definition":{ "function":{ "name":"author_full_name", "schema":"public" }, "table_argument":"author_row" } } }
-
Query the data from
authortable along with its computed fields.query { author { id first_name last_name full_name } }
Response:
{ "data": { "author": [ { "id": 1, "first_name": "Chris", "last_name": "Raichael", "full_name": "Chris Raichael" } ] } }
Please see docs to learn more about computed fields and their metadata API.
Create permissions with conditions spanning tables 🔐
This change allows you to use data in unrelated tables to build a permission rule using the new _exists keyword. Let's use an example to see how this works:
Say you have the following two tables:
-
usersColumns Type id Integer is_admin Boolean -
accountsColumns Type id Integer account_info Text
and you want to restrict access to the accounts table to only those users who are "admins" i.e. the value of the is_admin column is true for the given user_id (which is sent in the X-Hasura-User-Id session variable).
To compose a permission rule for this use-case, you can check if there's a row in the users table where id = X-Hasura-User-Id and is_admin = true:

Like all the other operators, you can use logical operators (_and, _or and _not) to further restrict access to a subset of the rows.
Performance optimisations
Compress HTTP responses 🗜️
HTTP responses from Hasura are now compressed (using gzip) by default whenever supported by the requesting client. In anecdotal tests, we've noticed approximately 10X compression in response payloads with negligible overhead for handling compression in the server and in client apps.
This should be especially useful to handle introspection queries on large datasets. We haven't yet benchmarked these changes in scenarios where network latency is a significant factor in overall latency, and any reports from the community on this front will be much appreciated!
Optmization for all subscriptions 🎚
The previous iteration of this change only optimised subscriptions that did not use non-scalar variables. This has now been fixed, and requests with non-scalar variable values, such as the following, are now multiplexed if they generate the same SQL:
subscription latest_tracks($condition: tracks_bool_exp!) {
tracks(where: $tracks_bool_exp) {
id
title
}
}Annotate GraphQL schema for better documentation 🖍
You can now annotate your GraphQL schema for better readability by adding comments to your Postgres schema elements i.e. tables, views, columns and functions. These comments will be displayed in the Docs window of GraphiQL:

Note: Currently, you can add comments for tables, views and column names using the console, but for functions you'll need to run a SQL query that does the same (support for this will be added to the console shortly).
Update conditionally when using upsert (where clause in on_conflict input object)
When using upsert, you can now conditionally update only a subset of rows using the new optional where clause in the on_conflict input object. Here's an example mutation:
mutation {
insert_item(
objects: {itemId:"1234", creationEpochSeconds: 1567026834},
on_conflict: {
constraint: item_pkey,
update_columns: [itemId, creationEpochSeconds]
where: {creationEpochSeconds: {_lt: 1567026834 }}
}) {
affected_rows
}
}Better support for Postgres co...
v1.0.0-beta.7
Changelog
🚨 This was a buggy release, please avoid running this release 🚨
EDIT: Oct 10, 2019 - 21:05 GMT+05:30: We have taken down the image from Docker hub following a couple of bug reports. latest tags now points to beta.6. If you have already upgraded to beta.7, you can downgrade to beta.6 after running the following SQL: https://gist.github.com/0x777/4e608a975ed4efeef6ac94ea329a4e80
EDIT: Oct 10 2019 - 15:30 GMT+05:30: We have identified a potential issue with this release. Please do not upgrade until we put out another notice.
- server: fix a typo in limit description of schema (close #2810) (#2811)
- server: allow creating permissions with conditions spanning tables (close #2512) (#2701)
- server: support optional parameters in database url (close #1709) (#2344)
- server: Implemented graceful shutdown for websockets (#2827)
- server: fix row comparison operator in event triggers (fix #2036) (#2868)
- server: propagate Postgres table comments to GraphQL schema descriptions (close #446) (#2397)
- server: Add Data.Time.Clock.Units for DiffTime literals and conversions
- server: Multiplex all subscriptions, grouping them by their resolved SQL query
- server: Change the way we determine whether or not queries are reusable
- server: server: Don’t allow warnings when building in CI (#2892)
- server: allow customising graphql schema for a table (close #981) (#2509)
- server: add gzip brotli compression to http responses (close #2674) (#2751)
- server: add brotli shared lib to packager image (#2924)
- server: Parameterize all SQL values when multiplexing subscription queries (#2942)
- server: Fix typo in warning message (#2949)
- server: fix hpc combine error (close #2946) (#2947)
- server: update custom column names on renaming/dropping columns (#2933)
- server: remove conflict_action type (#2950)
- server: fixes to the subscriptions improvements introduced with #2942 (#3005)
- server: fix SQL generation if more than one aggregate order_by items present, fix #2981 (#2998)
- server: remove brotli compression (#2967)
- server: add raw query field for error http log (close #2963) (#3020)
- server: support where clause in on_conflict of insert mutation (close #2795) (#3002)
- cli: check for empty response on migration settings (#2877)
- cli: optimise migrate api for console on cli (#2895)
- cli: allow customising graphql schema for a table (close #981) (#2509)
- console: add console support for setting table as enum (close #2767) (#2789)
- console: update enums docs (#2813)
- console: handle "without time zone" dateTime types in permissions builder (close #2842) (#2844)
- console: fix remote schema headers configuration in console (#2847)
- console: fix console insert/edit row glitches (close #2840, #2665) (#2843)
- console: make destructive actions on console require typed out confirmation (close #1469) (#2400)
- console: fix typos in documentation (#2562)
- console: update console telemetry config (#2899)
- console: add console support for exists operator in permissions (close #2837) (#2878)
- console: fix console server-build script (#2790)
- console: better key persistence in console (#2686)
- console: fix typos (#2935)
- console: updated heroku url property in console readme (#2957)
- console: fix console lint issues, code formatting (#3028)
- console: allow only tracked tables in manual relationship definition in console (#3046)
- console: separate server and cli env variables in console local dev (#2937)
- console: update graphiql explorer in hasura console and graphiql online (closes #2313) (#2994)
- console: fix console README and isProduction check while setting globals (#3076)
v1.0.0-beta.6
Changelog
EDIT(10-Sept): Breaking change
A minor breaking change with this release has been identified; some type names have been modified to make them more consistent with others. Here's a list of modified type-names:
integer_comparison_exp->Int_comparison_expboolean_comparison_exp->Boolean_comparison_expreal_comparison_exp->Float_comparison_exptext_comparison_exp->String_comparison_expvarchar_comparison_exp->String_comparison_exp
Support for GraphQL Enums
Single-column Postgres tables (or two-columns, where the second column is a documentation comment) can now be exposed as Enums in the GraphQL schema so that enum values can be explicitly represented and typechecked.
Creating Enums
Here's how you can configure Enums:
🎛 Using metadata APIs
- Adding a new table as Enums: An optional
is_enumkey has been added to thetrack_tablemetadata API that lets you specify that a table is to be exposed as an Enum. - Setting an existing tracked table as Enum: A new
set_table_is_enummetadata API allows specifying whether an already-tracked table should be used as an Enum table.
🖥 Using the console
- Adding a new table as Enums
- Create a table as usual (the table must have only 1 or 2 columns) and add some data in it:
Let's say we want to create an Enum for months of the year:Let's also add some test data into this table:CREATE TABLE months_of_the_year ( month text PRIMARY KEY, description text );
INSERT INTO months_of_the_year (month, comment) VALUES ('January', 'named after the Latin word for door (ianua)'), ('February', 'named after the Latin term februum, which means purification')
- Head to the
Modifysection for the table and toggle theSet table as enumoption and confirm.
- Create a table as usual (the table must have only 1 or 2 columns) and add some data in it:
- Exposing an existing tracked table as Enum
- Head to the
Modifysection for the table and toggle theSet table as enumoption and confirm.
- Head to the

Note: The GraphQL Spec mandates that you not have empty Enum lists (in this case, tables). Using any of the above methods with empty tables will result in an error.
Using Enums
- To restrict values for a column in a table to those from an enum, first, you need to set up a foreign key to the column of the enum table with the enum values
- If the enum table has been tracked and set as an enum table, the GraphQL schema will be updated to reflect Enums and the references to it in tables:
type rain_log { id: Int! rainfall: Numeric! month: months_of_the_year_enum! } enum months_of_the_year_enum { "named after the Latin word for door (ianua)" January "named after the Latin term februum, which means purification" February }
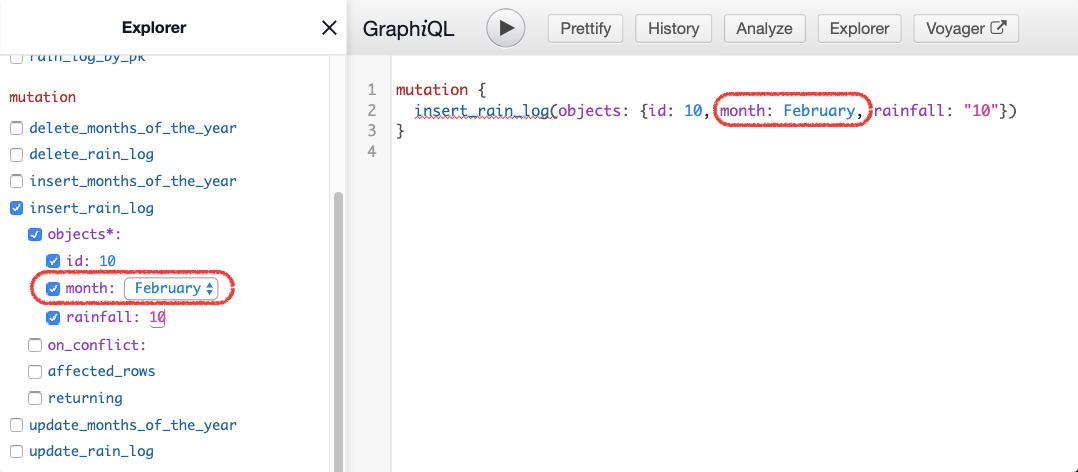
- If you head to Graphiql, you'll notice that:
- you can pick the enum value in Explorer from a drop-down
- you can use the name of the enum value directly rather than providing a string
🧭 🗺 Support for Raster ST_Intersect functions
Some of the overloaded variants of the PostGIS raster ST_Intersects function are now available as the following GraphQL operators for raster columns in boolean expressions:
_st_intersects_rast->boolean ST_Intersects(raster <raster-col>, raster <raster-input>)_st_intersects_nband_geom->boolean ST_Intersects(raster <raster-col>, integer nband, geometry geommin)_st_intersects_geom_nband->boolean ST_Intersects(raster <raster-col> , geometry geommin, integer nband=NULL)(with and without nband values)
Usage:
query ($raster_input: raster) {
table_with_raster_col(where: {rast_col: {_st_intersects_rast: $raster_input}}){
id
rast_col
}
}Note: raster_input is a raw String value of raster data.
Please see docs for more details.
🛠️ Bug Fixes and other changes
-
The server now uses named notation instead of positional notation for function arguments to prevent issues with the generated SQL if any of the arguments is not specified. (fix #2730) (#2777)
-
The server now shuts down gracefully for HTTP requests i.e. it stops accepting new connections, waits for all connections to be drained before shutting down. It also forcefully kills all pending connections after 30 seconds. This change does not deal with gracefully shutting down websocket connections, something that will be handled in a subsequent PR. 📣 Shoutout to @lorenzo for submitting this PR 🙏 🎉 (close #2698) (#2717)
-
Minor fixes in console & CLI (#2527, #2536, #2798, #2765, #2763, #2617)
v1.0.0-beta.5
Changelog
Enhancements
- The console now provides a summary view of permissions defined across roles in each schema. This summary interface can also be used to copy all permissions for a role in a schema to a new or existing role (#2693)
- The recently introduced templated "Frequently used columns" in the console are now available in the
Modifysection of a table too (close #2545) (#2593) - Better console notifications are now shown for errors in db schema load & metadata reload (#2658)
- Styles of data tables in console updated for better readability (#2629)
- The "secure-your-endpoint" docs link in the console now opens in a new tab (#2709)
- Remote schema definition now supports an optional
timeout_secondsargument to configure timeouts for calls (close #2501) (#2753)
Bug fixes
- All
Set-Cookieheaders are now read from a remote schema response and forwarded to the client (fix #2688) (#2739) - Postgres error code 22025 is captured as
HTTP 400bad request (close #2486) (#2671) - The type of a column whose permissions defined only with session variables can now be altered (close #2070) (#2683)
- Only the
ExceptionContentpart of an HTTP Exception is now sent to the client (#2738) - null values in
order_byinput field do not throw an error anymore (fix #2754) (#2755)
Build system, code clean-up and other misc. changes
Tests & build system (#2472,#2547, #2685, #2712, #2742)
Code cleanup (#2661, #2670, #2762, #2708, #2668, #2684, #2676)