Dynamo는 분산 저장소입니다. 그 내부 동작을 설명합니다.
From: https://www.allthingsdistributed.com/2007/10/amazons_dynamo.html
Dynamo에 대한 가정과 요구사항은 다음과 같습니다.
쿼리 모델 : 키로 고유하게 식별되는 데이터에 대한 간단한 읽기 및 쓰기 작업입니다. 상태는 고유 키로 식별되는 바이너리로 저장됩니다. 작업이 여러 데이터에 걸쳐 있지 않으며 관계형 스키마가 필요하지 않습니다. 이 요구 사항은 Amazon 서비스의 상당 부분이 이 간단한 쿼리 모델로 작동할 수 있으며 관계형 스키마가 필요하지 않다는 것을 기반으로 합니다. Dynamo는 비교적 작은(일반적으로 1MB 미만) 객체를 저장해야 하는 애플리케이션을 대상으로 합니다.
ACID 속성: ACID (Atomicity, Consistency, Isolation, Durability)는 데이터베이스의 트랜잭션이 안정적으로 처리되는 것을 보장하는 방법입니다. 데이터베이스 컨텍스트에서 데이터에 대한 단일 논리 작업을 트랜잭션이라고 합니다. Amazon의 경험에 따르면 ACID 보장을 제공하는 데이터 저장소는 가용성이 떨어지는 경향이 있습니다. 이는 업계와 학계에서 널리 인정받고 있습니다[5]. Dynamo는 일관성(ACID의 "C")을 일부 포기하여 고가용성을 달성합니다. Dynamo는 어떤 isolation(격리)을 제공하지 않으며 단일 키 업데이트만 허용합니다.
TBD
프로덕션 시스템에서 사용되는 데이터 복제 알고리즘은 Strong Consistant한 데이터 액세스 인터페이스를 제공하기 위해 예전부터 동기로 복제를 실행하고 있었습니다(synchronous replication). dynamo db가 목표한 consistency를 달성하기 위해 이러한 알고리즘은 특정 오류 시나리오에서 데이터 가용성을 희생해야합니다. 예를 들어, 답변의 정확성에 대한 불확실성을 다루기보다 데이터가 정확하다는 것이 절대적으로 확신될 때까지 데이터를 사용할 수 없게 됩니다. 초창기 데이터베이스 Replication에 관한 연구에서 확인할 수 있다시피, 네트워크 장애 가능성을 처리할 때 강력한 일관성과 높은 데이터 가용성을 동시에 달성할 수 없다는 것은 잘 알려져 있습니다[2, 11]. 이런 시스템과 응용 프로그램은 어떤 조건에서 어떤 속성을 달성할 수 있는지 알아야 합니다.
서버 및 네트워크 오류가 발생하기 쉬운 시스템의 경우, availability의 경우 사항이 백그라운드에서 레플리카로 전파되도록 허용하고 연결이 끊긴 동시 작업이 허용되는 optimistic replication를 이용해서 향상시킬 수 있습니다. 이 접근 방식의 문제는 감지하고 해결해야 하는 conflict change로 이어질 수 있다는 것입니다. 이러한 conflict resolution 프로세스는 두 가지 문제를 야기합니다. 누가, 언제 conflict를 해결하는지입니다. Dynamo는 eventually consistent한 데이터 저장소로 설계되었습니다. 모든 업데이트는 결국 모든 레플리카에 도달합니다.
중요한 설계 고려사항 중 하나는 conflict된 update 해결 프로세스를 실행할 시점입니다. (i.e. 읽기 또는 쓰기 중에 충돌을 해결해야하는지 여부) 많은 전통적인 데이터 저장도는 conflict resolution을 쓰는 시점에 실행하고, 읽는 시간(complexity)을 짧게 유지합니다[7]. 이러한 시스템에서 쓰는 동작은 데이터 저장소가 모든 Replica에 데이터를 복제하지 못했다면 아마도 거부(rejected)될 수 있습니다. 하지만 Dynamo는 항상 쓸 수 있는 데이터 저장소를 목표로합니다. (i.e. write에 고가용성인 데이터 스토어) 많은 아마존의 서비스에서, 고객의 update를 거부한다면 고객 경험을 해칠 것 입니다. 예를 들어, 쇼핑카트 서비스는 네트워크 및 서버 장애가 발생해도 고객이 항목을 추가 및 제거를 할 수 있어야합니다.
그 다음 설계 고려사항은 conflict resolution을 수행하는 주체입니다. 수행하는 주체는 데이터 스토어나 어플리케이션이 될 수 있습니다. 만약 데이터 스토어에서 conflict resolution를 수행한다면 선택 사항이 조금 제한됩니다. 이러한 케이스에서 데이터 스토어는 update conflict를 해결하기 위해 "마지막에 write가 이긴다[22]"와 같은 간단한 정책만 사용할 수 있습니다. 한편으로, 데이터 스키마를 알고 있는 어플리케이션은 고객의 경험을 위해 가장 적절한 conflict resolution 방법을 결정할 수 있습니다. 예를 들어, 고객 장바구니를 관리하는 애플리케이션은 conflict된 버전을 "병합-merge"하고 하나로 합쳐진 장바구니를 반환하도록 선택할 수 있습니다. 이러한 유연성에도 불구하고 일부 어플리케이션 개발자는 자체 conflict resolution 메커니즘을 작성하기를 원하지 않고 데이터 저장소에 그냥 저장합니다. 그러면 데이터 저장소는 "마지막 쓰기 승리"와 같은 간단한 정책을 선택할 수 밖에 없습니다.
From Pekora
Lock을 사용하지 못하고 가장 마지막에 들어온걸 채택하는 것은 Cassadra에서도 사용하는듯. 그렇다고 Conflict 처리를 클라이언트로 맡기면 클라이언트가 더러워진다.
설계에 포함된 다른 주요 원칙은 다음과 같습니다.
점진적인 확장성(Incremental scalability): Dynamo는 시스템 운영자와 시스템 그 자체에 영향을 최소화 하면서 한번에 하나의 스토리지 호스트(a.k.a 노드)가 확장 가능해야 합니다.
대칭성(Symmetry): Dynamo의 모든 노드는 각 노드별로 같은 역할을 가져야합니다. 구분되거나, 특별한 역할을 가지거나, 추가적인 역할을 담당하지 않습니다. 우리의 경험상, 대칭성은 시스템 프로비저닝 및 관리 프로세스를 단순화합니다.
분산된(Decentralization): 대칭에서 더 나아가, 설계에서 중앙 집중식 제어보다 분산된 P2P 기술을 선호해야 합니다. 과거에는 중앙 집중식 제어로 인해 중단(outages)이 발생하였으며, 우리의 목표는 가능한 그 상황을 피하는 것입니다. 이것은 더 단순하고, 확장가능하고, 가용성이 높은 시스템으로 이어집니다.
이질성(Heterogeneity): 시스템이 실행되는 인프라의 이질성(다른 점)을 이용할 수 있어야합니다. 예를 들어, 작업은 개별 서버의 용량(capability)에 비례해서 분배됩니다. 이는 모든 호스트를 한 번에 업그레이드할 필요 없이 용량이 큰 새 노드를 추가하는 데 필수적입니다.
상용 환경에서 운영이 필요한 스토리지 시스템의 아키텍처는 복잡합니다. 게다가, 실제 데이터 영속성 컴포넌트의 경우 시스템은 확장성(scalable), 방대한 로그 밸런싱, 실패 상황 디텍션, membership과 오류 감지, 레플리카와의 동기화, 오버로드 핸들링, 상태 전이, 동시성, 잡 스케줄링, 리퀘스트 변환(Marshalling), 요청 라우팅, 시스템 모니터링와 알람, 그리고 설정 관리가 필요합니다. 각 솔루션에 대한 디테일을 전부 설명하는건 어렵습니다. 따라서 이 글에서는 partitioning, replication, versioning, membership, failure handling and scaling와 같이 Dyanmo에서 사용된 코어 분신 시스템 테크닉에 집중하고 있습니다. 테이블 1은 Dynamo에서 사용된 기술들과 이점을 요약하고 있습니다.
| Problem | Technique | Advantage |
|---|---|---|
| Partitioning | Consistent Hashing | Incremental Scalability |
| High Availability for writes | Vector clocks with reconciliation during reads | Version size is decoupled from update rates. |
| Handling temporary failures | Sloppy Quorum and hinted handoff | Provides high availability and durability guarantee when some of the replicas are not available. |
| Recovering from permanent failures | Anti-entropy using Merkle trees | Synchronizes divergent replicas in the background. |
| Membership and failure detection | Gossip-based membership protocol and failure detection. | Preserves symmetry and avoids having a centralized registry for storing membership and node liveness information. |
Dynamo는 Key와 연관된 객체를 다음과 같은 간단한 인터페이스로 저장합니다. 이는 get()과 put()의 2가지 동작으로 이루어져있습니다. get(key)연산은 Key와 연관된 객체 복제본을 찾고 단일 개체 또는 충돌하는 버전의 개체 목록을 컨텍스트와 함께 반환합니다. put(key, context, object) 연산은 연결된 키를 기반으로 오브젝트의 복제본이 배치될 위치를 결정하고 복제본을 디스크에 기록합니다. 컨텍스트는 호출자가 불투명한 객체에 대한 시스템 메타데이터를 인코딩하고 객체의 버전과 같은 정보를 포함합니다. 컨텍스트 정보는 객체와 함께 저장되므로 시스템이 put요청에 제공된 컨텍스트 객체의 유효성을 확인할 수 있습니다.
Dynamo는 호출자가 제공한 키와 객체 둘 다 opaque array of bytes(from Peko: 내부 형태가 정의되지 않거나 데이터, 혹은 내부 정보가 외부로 공개되지 않은 데이터.) 로 간주합니다. 키에 MD5 해시를 적용하여 128비트 식별자를 생성합니다. 이 식별자는 키 서비스를 담당하는 스토리지 노드를 결정하는 데 사용됩니다.
Dynamo의 중요 디자인 요구사항중 하나는 반드시 점진적인 확장(Incremental Scalability)이 가능하다는 것입니다. 이를 위해서는 시스템의 노드 집합(i.e. 스토리지 호스트)을 통해 데이터를 동적으로 분할하는 메커니즘이 필요합니다. Dynamo의 파티션 스킴(from Peko: See Also: SQL Partitioning_Schemes)은 여러 스토리지 호스트에 로드를 분산하기 위해 일관된 해싱[10](consistent hashing)을 사용합니다. consistent hashing에서는 해시 함수의 결과 범위가 고정된 원형 공간 또는 "Ring"으로 처리됩니다. (i.e. 가장 큰 해시 값이 가장 작은 해시 값으로 랩핑됨) 시스템의 각 노드에는 Ring에서 "위치"를 나타내는 공간에 임의의 값이 할당됩니다. 키로 식별되는 각 데이터 항목은 Ring에서 위치를 양보하도록 데이터 항목의 키를 해시한 다음 링을 시계 방향으로 걸어 항목 위치보다 큰 첫 번째 노드를 찾아 노드에 할당됩니다. 따라서, 각 노드는 링의 이전 노드와 링 사이의 링의 영역에 대한 책임이 됩니다. 일관된 해싱의 주된 장점은 노드의 출발 또는 도착은 인접 노드에만 영향을 미치고 다른 노드는 영향을 받지 않는다는 것입니다.
기본적인 일관된 해싱 알고리즘은 몇 가지 문제가 존재합니다. 첫째, 링의 각 노드 위치에 데이터를 랜덤하게 할당하면 불균일한 데이터와 부하 분포를 초래합니다. 둘째, 기존 일관된 해싱 알고리즘은 노드 성능의 차이를 인식하지 못합니다. 이러한 문제를 해결하기 위해, Dynamo는 일관된 해싱의 변종([10, 20]에 사용된 것과 유사)을 사용합니다: 한 노드를 원의 단일 포인트에 매핑하는 대신, 각 노드가 링의 여러 포인트에 할당됩니다. 이를 위해 Dynamo는 "가상 노드"라는 개념을 사용합니다. 가상 노드는 시스템의 단일 노드처럼 보이지만 각 노드는 둘 이상의 가상 노드를 책임질 수 있습니다. 효과적으로, 새로운 노드가 시스템에 추가될 때, 그것은 링에서 여러 위치(A.K.A, 토큰)에 할당됩니다. (from Peko: 성능 좋은 노드가 여러 노드 역할을 할 수 있게 앞에 레이어를 하나 둔거라고 보면 된다.) Dynamo의 분할 계획을 미세 조정하는 프로세스는 섹션 6에 설명되어 있습니다.
가상 노드를 사용하는 것은 다음과 같은 장점이 있습니다:
- 만약 노드가 (장애나 정기적인 점검으로) 사용할 수 없게 된다면, 이 노드에서 처리하는 로드는 사용 가능한 나머지 노드에 균등하게 분산된다.
- 노드가 다시 사용할 수 있게 되었을 때, 혹은 새로운 노트가 시스템에 추가되었을 때, 새로 사용 가능한 노드는 사용 가능한 다른 노드 각각으로부터 비슷한정도의 로드를 받아들입니다.
- 노드가 담당하는 가상 노드 수는 물리적 인프라의 성능 차이를 고려하여 capacity에 따라 결정할 수 있습니다.
From Pekora
Consistent Hashing은 노드가 추가되는 것에 자유롭지 못하며, 노드마다 성능이 다른 경우 성능에 따라서 요청을 분산시키기 어렵다. 따라서 Dynamo는 이를 변형해서 사용한다.
Ring을 만들고, 가상의 자리를 마련한 뒤, 가상의 자리를 노드들이 점유하는 방식이다. 이렇게 하면 Ring에서 차지하는 범위를 조절할 수 있다.
일관된 해싱과 관련한 내용은 Consistancy Hashing를 참고해주세요.
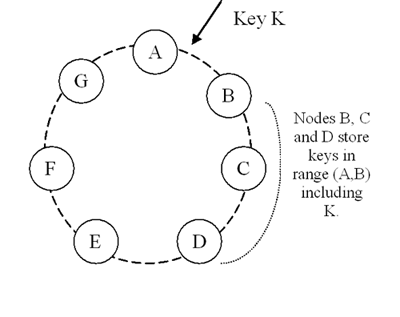
높은 가용성과 내구성을 이루기 위하여, Dynamo는 데이터를 여러 호스트에 복제합니다. 각 데이터는 N개의 호스트에 복제되며, N 값은 “per-instance”라는 파라미터로 설정됩니다. 또한 각 Key는 coordinator node에 할당됩니다. (이전 Section에서 설명함) 각 coordinator node는 해당 범위에 속하는 데이터 항목의 복제를 담당합니다. 범위 내에 각 키를 로컬에 저장하는 것 외에도 coordinator node는 링의 N-1 시계 방향 후속 노드들에게 이러한 키를 복제합니다. 이러한 방법을 사용해서 각 노드가 링에서 자신, 그리고 N번째 이전 노드 사이의 영역을 책임지게 되는 시스템을 만듭니다. 그림 2번에서, 노드 B는 자신이 담당하는 key를 로컬에 저장할 뿐만 아니라 노드 C, D에도 복제합니다. 노드 D는 노드 (A, B], (B, C], (C, D]에 해당하는 키를 저장합니다.
From Pekora
위에서 설명한 Ring방식의 Consistent Hashin을 사용하는 경우, Ring에 노드들이 위치된다. Ring은 순서가 있기 때문에, 그 다음 노드들에도 데이터를 저장하도록 한다면 결국 N개의 노드에 데이터를 복제해서 저장할 수 있다.
만약 한 노드가 죽더라도 Ring에서 다음에 위치한 노드에 데이터를 복제하였기 때문에, 그 다음 노드를 알아내서 데이터를 무리없이 가져올 수 있다.
특정한 키를 저장할 책임을 가진 노드의 리스트를 preference list 라고 불립니다. 시스템은 Section 4와 8에서 설명한 것과 같이 시스템의 모든 노드가 이 preference list에 있어야 할 노드를 결정할 수 있도록 디자인 됩니다. 노드 failures를 고려하기 위해, preference list는 N개의 노드보다 많이 포함합니다. 알아두어야할 점은 버추얼 노드를 사용하는 경우, Ring의 첫 N개의 다음 위치는 N개 미만의 물리적 노드가 점유할 것입니다. (i.e. 노드는 하나 이상의 첫번째 N 위치를 점유할 수 있습니다.) 이 문제를 해결하려면 key에 대한 preference list는 물리적 노드만 포함되도록 링의 위치를 건너뛰는 방식으로 구성됩니다.
From Pekora
Key가 여러 노드에 복제되어서 저장되기 때문에, Key를 찾을 수 있는 노드 리스트(aka preference list)를 갖고있는다.
버추얼 노드를 사용하기 때문에 Ring의 다음 위치 N개를 바로 사용하면 물리적 노드 N개보다 적은 숫자가 되어요.
Dynamo는 변경사항이 모든 레플리카에게 비동기적으로 전파되는 결과적 일관성을 제공합니다. Put()을 호출하면, 변경사항이 모든 레플리카에게 적용되기 전에 반환됩니다. 따라서 이어서 실행된 Get() operation에서 변경사항이 적용되지 않은 데이터를 반환할 수 있습니다. 만약 failures가 발생하지 않는다면, 변경사항이 적용되는데 시간 제한이 있습니다. 하지만, failures 시나리오에서는 (e.g. 서버 정전, 혹은 네트워크 파티션) 변경사항은 오랫동안 모든 레플리카에 도착하지 않을 수도 있습니다.
아마존 플랫폼에 있는 어플리케이션 종류중에는 이러한 데이터 불일치에 견딜 수 있고, 이러한 조건에서 작동하도록 구성할 수 있습니다. 예를 들어, 쇼핑카트 어플리케이션은 절대 삭제되거나 거부되지 않는 "카트에 추가" operation이 요구됩니다. 만약 대부분의 카트 상태가 이용할 수 없는 상태일 때, 유저들이 이전 버전의 카드를 변경할 수 있다면, 이 변경사항은 여전히 의미있으므로 적용되어야 합니다. 하지만 동시에 카트 상태가 현재 이용할 수 없는 상태로 대체되어서는 안 되며, 그 자체로 적용되어야 할 변경 사항이 포함될 수 있습니다. "카드에 추가" operation과 "카드에서 아이템 삭제"는 Dynamo에서 put 요청으로 변환됩니다. 고객이 쇼핑 카트에 아이템을 추가하는 것을 혹은 삭제하는 것을 원하는 경우, 쇼핑 카트의 가장 마지막 버전은 이용할 수 없다면, 아이템은 이전 버전의 카트에 추가(또는 이전 버전의 카트에서 제거)되고 다른 버전의 카트 상태는 나중에 조정됩니다.
From Pekora
만약 가장 최근 버전이 이용 불가능한 경우 이전 버전에 적용을 하고, 나중에 병합하는 방식인듯.
이런 종류의 보장을 제공하는 경우, Dynamo는 변화된 결과를 데이터의 새로운 불변 버전으로 취급합니다. 이것은 시스템이 같은 시점에 객체가 여러 버전으로 존재하는 것을 허용합니다. 대부분의 경우, 새로운 버전은 이전 버전(들)을 포함합니다. 그리고 시스템은 권위있는 버전을 스스로 정할 수 있습니다.(syntactic reconciliation)